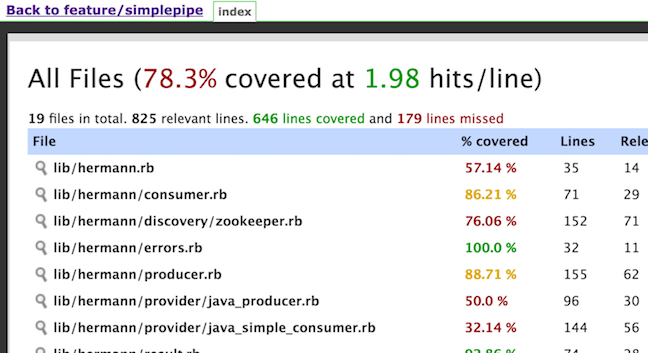
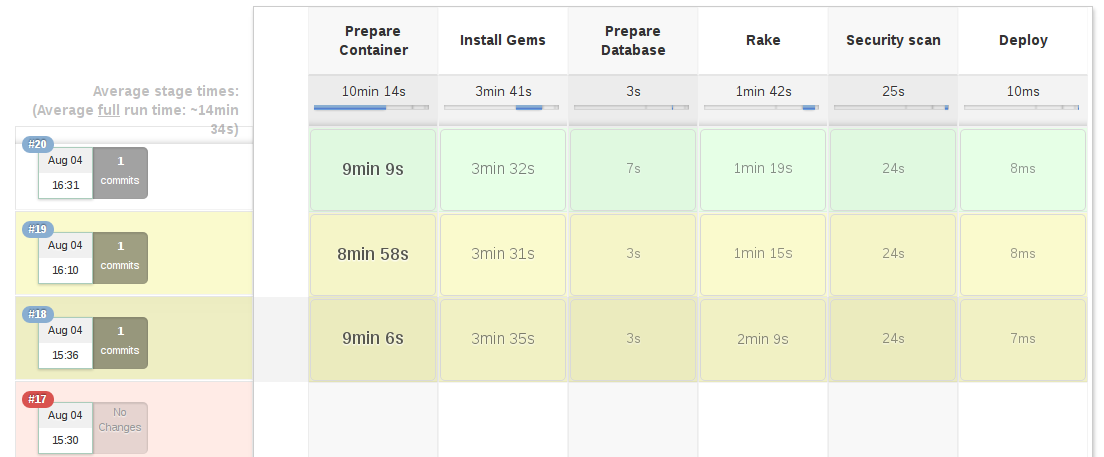
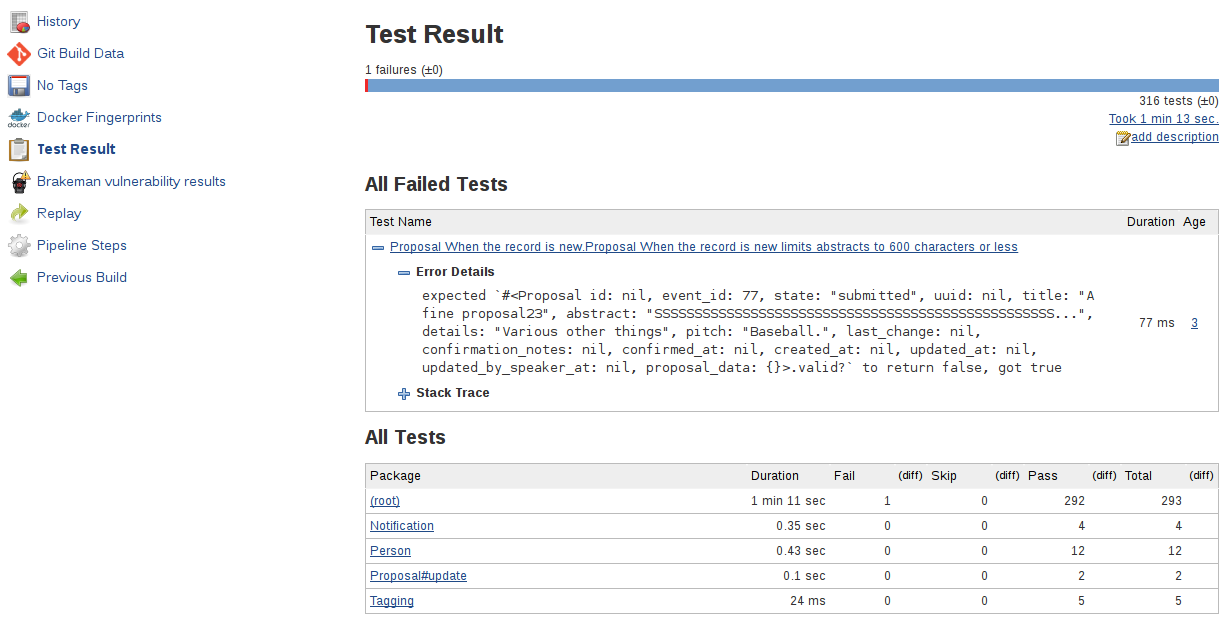
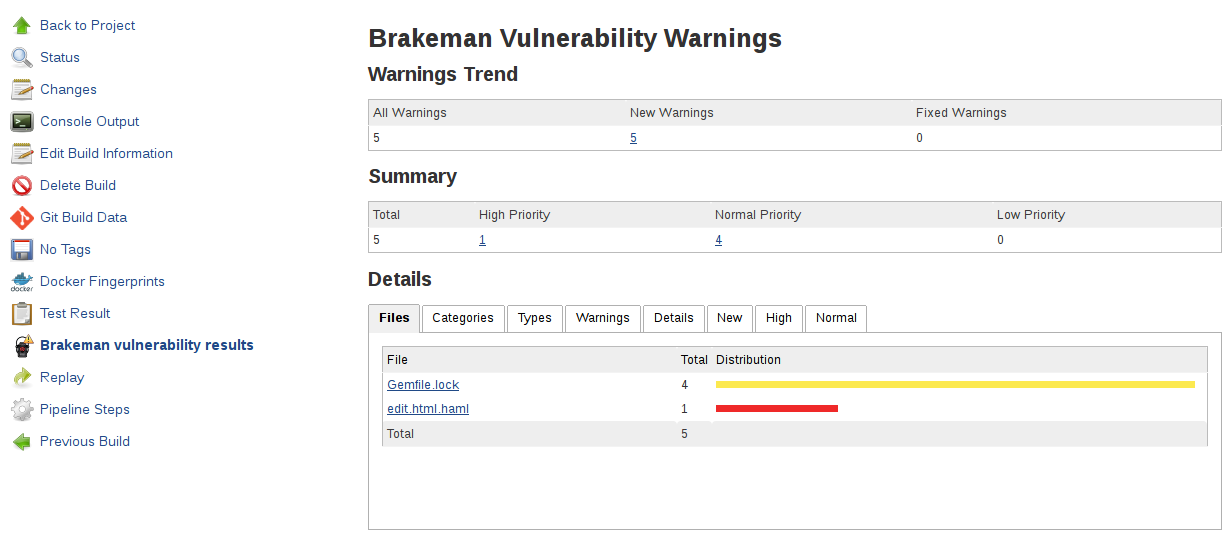
node { /* ...unchanged... */ }void runTests(def args) {/* Request the test groupings. Based on previous test results. *//* see https://wiki.jenkins-ci.org/display/JENKINS/Parallel+Test+Executor+Plugin and demo on github
/* Using arbitrary parallelism of 4 and "generateInclusions" feature added in v1.8. */def splits = splitTests parallelism: [$class: 'CountDrivenParallelism', size: 4], generateInclusions: true/* Create dictionary to hold set of parallel test executions. */def testGroups = [:]for (int i = 0; i < splits.size(); i++) {def split = splits[i]/* Loop over each record in splits to prepare the testGroups that we'll run in parallel. *//* Split records returned from splitTests contain { includes: boolean, list: List<String> }. *//* includes = whether list specifies tests to include (true) or tests to exclude (false). *//* list = list of tests for inclusion or exclusion. *//* The list of inclusions is constructed based on results gathered from *//* the previous successfully completed job. One additional record will exclude *//* all known tests to run any tests not seen during the previous run. */
testGroups["split-${i}"] = { // example, "split3"
node {
checkout scm/* Clean each test node to start. */
mvn 'clean'def mavenInstall = 'install -DMaven.test.failure.ignore=true'/* Write includesFile or excludesFile for tests. Split record provided by splitTests. *//* Tell Maven to read the appropriate file. */if (split.includes) {
writeFile file: "target/parallel-test-includes-${i}.txt", text: split.list.join("\n")
mavenInstall += " -Dsurefire.includesFile=target/parallel-test-includes-${i}.txt"
} else {
writeFile file: "target/parallel-test-excludes-${i}.txt", text: split.list.join("\n")
mavenInstall += " -Dsurefire.excludesFile=target/parallel-test-excludes-${i}.txt"
}/* Call the Maven build with tests. */
mvn mavenInstall/* Archive the test results */
step([$class: 'JUnitResultArchiver', testResults: '**/target/surefire-reports/TEST-*.xml'])
}
}
}
parallel testGroups
}/* Run Maven */void mvn(def args) { /* ... */ }