August 19, 2016, 12:42 pm
I am pleased to announce that we have partnered with Microsoft to migrate and
power the Jenkins project’s infrastructure with
Microsoft Azure. The partnership comes
at an important time, after the recent launch of Jenkins 2.0,
Jenkins users are more readily adopting Pipeline as
Code and many other plugins at an increasing rate, elevating the importance of
Jenkins infrastructure to the overall success of the project. That strong and
continued growth has brought new demands to our infrastructure’s design and
implementation, requiring the next step in its evolution. This partnership helps
us grow with the rest of the project by unifying our existing infrastructure
under one comprehensive, modern and scalable platform.
Currently we have infrastructure in four different locations, with four
different infrastructure providers, each with their own APIs and tools for
managing resources, each with varying capabilities and capacities.
Project infrastructure is managed by a team of volunteers, operating
more than 15 different services and managing a number of additional external
services.
Our current download/mirror network, while geographically distributed, is
relatively primitive and its implementation prevents us from using more modern
distribution best practices.
In essence, five years of tremendous growth for Jenkins has outpaced our
organically grown, unnecessarily complex, project infrastructure. Migrating to
Azure simplifies and improves our infrastructure in a dramatic way that would
not be possible without a comprehensive platform consisting of: compute, CDN,
storage and data-store services. Our partnership covers, at minimum, the next
three years of the project’s infrastructure needs, giving us a great home for
the future.
Azure also enables a couple of projects that I
have long been dreaming of providing to Jenkins users and contributors:
End-to-end TLS encrypted distribution of Jenkins packages, plugins and
metadata via the Azure CDN.
More complete build/test/release support and capacity onci.jenkins.io for plugin developers usingAzure
Container Service and generic VMs.
The Jenkins infrastructure is all open
source which means all of our Docker containers, Puppet code and many of our
tools are all available on GitHub. Not
only can you watch the migration process to Azure as it happens, but I also
invite you to participate in making our project’s infrastructure better (join
us in the #jenkins-infra channel on Freenode or ourmailing list).
Suffice it to say, I’m very excited about the bright [blue] future for the
Jenkins project and the infrastructure that powers it!
![]()
↧
August 19, 2016, 12:42 pm
About myself
My name is Alexandru Somai.
I’m following a major in Software Engineering at the Babes-Bolyai University of Cluj-Napoca, Romania.
I have more than two years hands-on experience working in Software Development.
I enjoy writing code in Java, Groovy and JavaScript.
The technologies and frameworks that I’m most familiar with are: Spring Framework, Spring Security, Hibernate,
JMS, Web Services, JUnit, TestNG, Mockito.
As build tools and continuous integration, I’m using Maven and Jenkins.
I’m a passionate software developer who is always learning, always looking for new challenges.
I want to start contributing to the open source community and Google Summer of Code is a starting point for me.
Project summary
Currently, Jenkins’ build workspace may become very large in size due to the fact that some compilers generate
very large volumes of data.
The existing plugins that share the workspace across builds are able to do this by copying the files from
one workspace to another, process which is inefficient.
A solution is to have a Jenkins plugin that is able to manage and reuse the same workspace between multiple builds.
As part of the Google Summer of Code 2016 I will be working on
the External Workspace Manager plugin.
My mentors for this project are Oleg Nenashev
and Martin d’Anjou.
This plugin aims to provide an external workspace management system.
It should facilitate workspace share and reuse across multiple Jenkins jobs.
It should eliminate the need to copy, archive or move files.
The plugin will be written for Pipeline jobs.
Usage
Prerequisites
Multiple physical disks accessible from Master.
The same physical disks must be accessible from Jenkins Nodes (renamed to Agents in Jenkins 2.0).
In the Jenkins global configuration, define a disk pool (or many) that will contain the physical disks.
In each Node configuration, define the mounting point from the current node to each physical disk.
The following diagram gives you an overview of how an External Workspace Manager configuration may look like:
Example one
Let’s assume that we have one Jenkins job. In this job, we want to use the same workspace on multiple Jenkins nodes.
Our pipeline code may look like this:
stage ('Stage 1. Allocate workspace')def extWorkspace = exwsAllocate id: 'diskpool1'
node ('linux') {
exws (extWorkspace) {
stage('Stage 2. Build on the build server')
git url: '...'
sh 'mvn clean install'
}
}
node ('test') {
exws (extWorkspace) {
stage('Stage 3. Run tests on a test machine')
sh 'mvn test'
}
}
Note: The stage() steps are optional from the External Workspace Manager plugin perspective.
Stage 1. Allocate workspace
The exwsAllocate step selects a disk from diskpool1
(default behavior: the disk with the most available size).
On that disk, let’s say disk1, it allocates a directory.
The computed directory path is: /physicalPathOnDisk/$JOB_NAME/$BUILD_NUMBER.
For example, Let’s assume that the $JOB_NAME is integration and the $BUILD_NUMBER is 14.
Then, the resulting path is: /jenkins-project/disk1/integration/14.
Stage 2. Build on the build server
All the nodes labeled linux must have access to the disks defined in the disk pool.
In the Jenkins Node configurations we have defined the local paths that are the mounting points to each disk.
The exws step concatenates the node’s local path with the path returned by the exwsAllocate step.
In our case, the node labeled linux has its local path to disk1 defined as: /linux-node/disk1/.
So, the complete workspace path is: /linux-node/disk1/jenkins-project/disk1/integration/14.
Stage 3. Run tests on a test machine
Further, we want to run our tests on a different node, but we want to reuse the previously created workspace.
In the node labeled test we have defined the local path to disk1 as: /test-node/disk1/.
By applying the exws step, our tests will be able to run in the same workspace as the build.
Therefore, the path is: /test-node/disk1/jenkins-project/disk1/integration/14.
Example two
Let’s assume that we have two Jenkins jobs, one called upstream and the other one called downstream.
In the upstream job, we clone the repository and build the project, and in the downstream job we run the tests.
In the downstream job we don’t want to clone and re-build the project, we need to use the same
workspace created in the upstream job.
We have to be able to do so without copying the workspace content from one location to another.
The pipeline code in the upstream job is the following:
stage ('Stage 1. Allocate workspace in the upstream job')def extWorkspace = exwsAllocate id: 'diskpool1'
node ('linux') {
exws (extWorkspace) {
stage('Stage 2. Build in the upstream job')
git url: '...'
sh 'mvn clean install'
}
}
And the downstream's pipeline code is:
stage ('Stage 3. Allocate workspace in the downstream job')def extWorkspace = exwsAllocate id: 'diskpool1', upstream: 'upstream'
node ('test') {
exws (extWorkspace) {
stage('Stage 4. Run tests in the downstream job')
sh 'mvn test'
}
}
Stage 1. Allocate workspace in the upstream job
The functionality is the same as in example one - stage 1.
In our case, the allocated directory on the physical disk is: /jenkins-project/disk1/upstream/14.
Stage 2. Build in the upstream job
Same functionality as example one - stage 2.
The final workspace path is: /linux-node/disk1/jenkins-project/disk1/upstream/14.
Stage 3. Allocate workspace in the downstream job
By passing the upstream parameter to the exwsAllocate step,
it selects the most recent stable upstream workspace (default behavior).
The workspace path pattern is like this: /physicalPathOnDisk/$UPSTREAM_NAME/$MOST_RECENT_STABLE_BUILD.
Let’s assume that the last stable build number is 12, then the resulting path is:/jenkins-project/disk1/upstream/12.
Stage 4. Run tests in the downstream job
The exws step concatenates the node’s local path with the path returned by the exwsAllocate step in stage 3.
In this scenario, the complete path for running tests is: /test-node/disk1/jenkins-project/disk1/upstream/12.
It will reuse the workspace defined in the upstream job.
Additional details
You may find the complete project proposal, along with the design details, features, more examples and use cases,
implementation ideas and milestones in the design document.
The plugin repository will be available on GitHub.
A prototype version of the plugin should be available in late June and the releasable version in late August.
I will be holding plugin functionality demos within the community.
I do appreciate any feedback.
You may add comments in the design document.
If you are interested to have a verbal conversation, feel free to join our regular meetings on Mondays at12:00 PM UTC
on the Jenkins hangout.
I will be posting updates from time to time about the plugin status on theJenkins developers mailing list.
![]()
↧
↧
August 19, 2016, 12:42 pm
|
This is a guest post by Chris Price.
Chris is a software engineer at Puppet, and has been
spending some time lately on automating performance testing using the latest
Jenkins features. |
In this blog post, I’m going to attempt to provide some step-by-step notes on
how to refactor an existing Jenkins plugin to make it compatible with the new
Jenkins Pipeline jobs. Before we get to the fun stuff, though, a little
background.
How’d I end up here?
Recently, I started working on a project to automate some performance tests for
my company’s products. We use the awesome Gatling load
testing tool for these tests, but we’ve largely been handling the testing very
manually to date, due to a lack of bandwidth to get them automated in a clean,
maintainable, extensible way. We have a years-old Jenkins server where we use
the gatling jenkins
plugin to track the
history of certain tests over time, but the setup of the Jenkins instance was
very delicate and not easy to reproduce, so it had fallen into a state of
disrepair.
Over the last few days I’ve been putting some effort into getting things more
automated and repeatable so that we can really maximize the value that we’re
getting out of the performance tests. With some encouragement from the fine
folks in the #jenkinsIRC channel, I ended up exploring
the JobDSL
plugin and the new Pipeline jobs. Combining those two
things with some Puppet code to provision a Jenkins server via thejenkins puppet module gave me
a really nice way to completely automate my Jenkins setup and get a seed job in
place that would create my perf testing jobs. And the Pipeline job format is
just an awesome fit for what I wanted to do in terms of being able to easily
monitor the stages of my performance tests, and to make the job definitions
modular so that it would be really easy to create new performance testing jobs
with slight variations.
So everything’s going GREAT up to this point. I’m really happy with how it’s
all shaping up. But then… (you knew there was a "but" coming, right?) I
started trying to figure out how to add the
Gatling Jenkins
plugin to the Pipeline jobs, and kind of ran into a wall.
As best as I could tell from my Googling, the plugin was probably going to
require some modifications in order to be able to be used with Pipeline jobs.
However, I wasn’t able to find any really cohesive documentation that
definitively confirmed that or explained how everything fits together.
Eventually, I got it all sorted out. So, in hopes of saving the next person a
little time, and encouraging plugin authors to invest the time to get their
plugins working with Pipeline, here are some notes about what I learned.
Spoiler: if you’re just interested in looking at the individual git commits that
I made on may way to getting the plugin working with Pipeline, have a look at
this github
branch.
Creating a pipeline step
The main task that the Gatling plugin performs is to archive Gatling reports
after a run. I figured that the end game for this exercise was that I was going
to end up with a Pipeline "step" that I could include in my Pipeline scripts, to
trigger the archiving of the reports. So my first thought was to look for an
existing plugin / Pipeline "step" that was doing something roughly similar, so
that I could use it as a model. The Pipeline "Snippet Generator" feature
(create a pipeline job, scroll down to the "Definition" section of its
configuration, and check the "Snippet Generator" checkbox) is really helpful for
figuring out stuff like this; it is automatically populated with all of the
steps that are valid on your server (based on which plugins you have installed),
so you can use it to verify whether or not your custom "step" is recognized, and
also to look at examples of existing steps.
Looking through the list of existing steps, I figured that the archive step
was pretty likely to be similar to what I needed for the gatling plugin:
publicclassGatlingArchiverStepextends AbstractStepImpl {@DataBoundConstructorpublic GatlingArchiverStep() {}@ExtensionpublicstaticclassDescriptorImplextends AbstractStepDescriptorImpl {public DescriptorImpl() { super(GatlingArchiverStepExecution.class); }@OverridepublicString getFunctionName() {return"gatlingArchive";
}@Nonnull@OverridepublicString getDisplayName() {return"Archive Gatling reports";
}
}
}
Note that in that commit I also added a config.jelly file. This is how you
define the UI for your step, which will show up in the Snippet Generator. In
the case of this Gatling step there’s really not much to configure, so my
config.jelly is basically empty.
With that (and the rest of the code from that commit) in place, I was able to
fire up the development Jenkins server (via mvn hpi:run, and note that you
need to go into the "Manage Plugins" screen on your development server and
install the Pipeline plugin once before any of this will work) and visit the
Snippet Generator to see if my step showed up in the dropdown:
This step doesn’t actually do anything yet, but it’s recognized by Jenkins and
can be included in your pipeline scripts at that point, so, we’re on our way!
The step that we created above is a first-class DSL addition that can be used in
Pipeline scripts. There’s another way to make your plugin work usable from a
Pipeline job, without making it a first-class build step. This is by use of the
step "metastep", mentioned in the pipeline-plugin
DEVGUIDE.
When using this approach, you simply refactor your Builder or Publisher to
extend SimpleBuildStep, and then you can reference the build step from the
Pipeline DSL using the step method.
In the Jenkins GUI, go to the config screen for a Pipeline job and click on the
Snippet Generator checkbox. Select step: General Build Step from the
dropdown, and then have a look at the options that appear in the Build Step
dropdown. To compare with our previous work, let’s see what "Archive the
artifacts" looks like:
From the snippet generator we can see that it’s possible to trigger an Archive
action with syntax like:
step([$class: 'ArtifactArchiver', artifacts: 'foo*', excludes: null])
This is the "metastep". It’s a way to trigger any build action that implements
SimpleBuildStep, without having to actually implement a real "step" that
extends the Pipeline DSL like we did above. In many cases, it might only make
sense to do one or the other in your plugin; you probably don’t really need
both.
For the purposes of this tutorial, we’re going to do both. For a couple of reasons:
Why the heck not? :) It’s a good demonstration of how the metastep stuff
works.
Because implementing the "for realz" step will be a lot easier if the Gatling
action that we’re trying to call from our gatlingArchive() syntax is using the
newer Jenkins APIs that are required for subclasses of SimpleBuildStep.
GatlingPublisher is the main build action that we’re interested in using in
Pipeline jobs. So, with all of that in mind, here’s our next goal: get
step([$class: 'GatlingPublisher', ...) showing up in the Snippet Generator.
The javadocs for the SimpleBuildStep
class
have some notes on what you need to do when porting an existing Builder orPublisher over to implement the SimpleBuildStep interface. In all
likelihood, most of what you’re going to end up doing is to replace occurrences
of AbstractBuild with references to the Run class, and replace occurrences
of AbstractProject with references to the Job class. The APIs are pretty
similar, so it’s not too hard to do once you understand that that’s the game.
There is some discussion of this in the pipeline-plugin
DEVGUIDE.
After making these changes, I fired up the development Jenkins server, and, voila!
So, now, we can add a line like this to a Pipeline build script:
step([$class: 'GatlingPublisher', enabled: true])
And it’ll effectively be the same as if we’d added the Gatling "Post-Build
Action" to an old-school Freestyle project.
Build Actions vs. Project Actions
At this point our modified Gatling plugin should work the same way as it always
did in a Freestyle build, but in a Pipeline build, it only partially works.
Specifically, the Gatling plugin implements two different "Actions" to surface
things in the Jenkins GUI: a "Build" action, which adds the Gatling icon to the
left sidebar in the GUI when you’re viewing an individual build in the build
history of a job, and a "Project" action, which adds that same icon to the left
sidebar of the GUI of the main page for a job. The "Project" action also adds a
"floating panel" on the main job page, which shows a graph of the historical
data for the Gatling runs.
In a Pipeline job, though, assuming we’ve added a call to the metastep, we’re
only seeing the "Build" actions. Part of this is because, in the last round of
changes that I linked, we only modified the "Build" action, and not the
"Project" action. Running the metastep in a Pipeline job has no visible effect
at all on the project/job page at this point. So that’s what we’ll tackle next.
The key thing to know about getting "Project" actions working in a Pipeline job
is that, with a Pipeline job, there is no way for Jenkins to know up front what
steps or actions are going to be involved in a job. It’s only after the job
runs once that Jenkins has a chance to introspect what all the steps were. As
such, there’s no list of Builders or Publishers that it knows about up front to
call getProjectAction on, like it would with a Freestyle job.
This is whereSimpleBuildStep.LastBuildAction
comes into play. This is an interface that you can add to your Build actions,
which give them their own getProjectActions method that Jenkins recognizes and
will call when rendering the project page after the job has been run at least
once.
The build action class now constructs an instance of the Project action and
makes it accessible via getProjectActions (which comes from theLastBuildAction interface):
publicclassGatlingBuildActionimplementsAction, SimpleBuildStep.LastBuildAction {public GatlingBuildAction(Run<?, ?> build, List<BuildSimulation> sims) {this.build = build;this.simulations = sims;List<GatlingProjectAction> projectActions = newArrayList<>();
projectActions.add(new GatlingProjectAction(build.getParent()));this.projectActions = projectActions;
}@OverridepublicCollection<? extendsAction> getProjectActions() {returnthis.projectActions;
}
}
After making these changes, if we run the development Jenkins server, we can see
that after the first successful run of the Pipeline job that calls theGatlingPublisher metastep, the Gatling icon indeed shows up in the sidebar on
the main project page, and the floating box with the graph shows up as well:
Making our DSL step do something
So at this point we’ve got the metastep syntax working from end-to-end, and
we’ve got a valid Pipeline DSL step (gatlingArchive()) that we can use in our
Pipeline scripts without breaking anything… but our custom step doesn’t
actually do anything. Here’s the part where we tie it all together… and it’s
pretty easy! All we need to do is to make our step "Execution" class
instantiate a Publisher and call perform on
it.
publicclassGatlingArchiverStepExecutionextends AbstractSynchronousNonBlockingStepExecution<Void> {@StepContextParameterprivatetransient TaskListener listener;@StepContextParameterprivatetransient FilePath ws;@StepContextParameterprivatetransient Run build;@StepContextParameterprivatetransient Launcher launcher;@OverrideprotectedVoid run() throwsException {
listener.getLogger().println("Running Gatling archiver step.");
GatlingPublisher publisher = new GatlingPublisher(true);
publisher.perform(build, ws, launcher, listener);returnnull;
}
}
After these changes, we can fire up the development Jenkins server, and hack up
our Pipeline script to call gatlingArchive() instead of the metastepstep([$class: 'GatlingPublisher', enabled: true]) syntax. One of these is
nicer to type and read than the other, but I’ll leave that as an exercise for
the reader.
Fin
With that, our plugin now works just as well in the brave new Pipeline world as
it did in the olden days of Freestyle builds. I hope these notes save someone
else a little bit of time and googling on your way to writing (or porting) an
awesome plugin for Jenkins Pipeline jobs!
![]()
↧
August 19, 2016, 12:42 pm
In recent years developers have become rapidly attracted to tools that are not
only functional but are designed to fit into their workflow seamlessly and are
a joy to use. This shift represents a higher standard of design and user
experience that Jenkins needs to rise to meet.
We are excited to share and invite the community to join us on a project we’ve
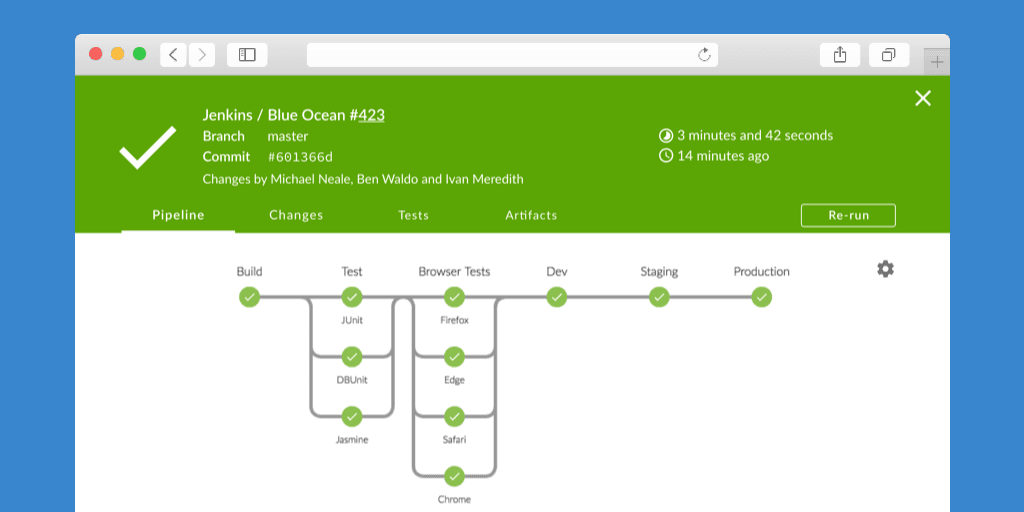
been thinking about over the last few months called Blue Ocean.
Blue Ocean is a project that rethinks the user experience of Jenkins, modelling
and presenting the process of software delivery by surfacing information that’s
important to development teams with as few clicks as possible, while still
staying true to the extensibility that is core to Jenkins.
While this project is in the alpha stage of development, the intent is that
Jenkins users can install Blue Ocean side-by-side with the Jenkins Classic UI
via a plugin.
Not all the features listed on this blog are complete but we will be hard at
work over the next few months preparing Blue Ocean for general use. We intend
to provide regular updates on this blog as progress is made.
Blue Ocean is open source today
and we invite you to give us feedback and to contribute to the project.
Blue Ocean will provide development teams:
New modern user experience
The UI aims to improve clarity, reduce clutter and navigational depth to make
the user experience very concise. A modern visual design gives developers much
needed relief throughout their daily usage and screens respond instantly to
changes on the server making manual page refreshes a thing of the past.
Advanced Pipeline visualisations with built-in failure diagnosis
Pipelines are visualised on screen along with the
steps and logs to allow simplified comprehension of the continuous delivery
pipeline – from the simple to the most sophisticated scenarios.
Scrolling through 10,000 line log files is a thing of the past. Blue Ocean
breaks down your log per step and calls out where your build failed.
Branch and Pull Request awareness
Modern pipelines make use of multiple Git branches, and Blue Ocean is designed
with this in mind. Drop a Jenkinsfile into your Git
repository that defines your pipeline and Jenkins will automatically discover
and start automating any Branches and validating Pull Requests.
Jenkins will report the status of your pipeline right inside Github or
Bitbucket on all your commits, branches or pull requests.
Personalised View
Favourite any pipelines, branches or pull requests and see them appear on your
personalised dashboard. Intelligence is being built into the dashboard. Jobs
that need your attention, say a Pipeline waiting for approval or a failing job
that you have recently changed, appear on the top of the dashboard.
You can read more about Blue Ocean and its goals on theproject page and developers should watch theDevelopers list for more information.
For Jenkins developers and plugin authors:
Jenkins Design “Language”
The Jenkins Design Language (JDL) is a set of standardised React components and
a style guide that help developers create plugins that retain the look and feel
of Blue Ocean in an effortless way. We will be publishing more on the JDL,
including the style guide and developer documentation, over the next few weeks.
The Jenkins plugin tool chain has been extended so that developers can useES6,React, NPM
in their plugins without endless yak-shaving. Jenkinsjs-modules are already in use in
Jenkins today, and this builds on this, using the same tooling.
Client side Extension points
Client Side plugins use Jenkins plugin infrastructure. The Blue Ocean libraries
built on ES6 and React.js provide an extensible client side component model
that looks familiar to developers who have built Jenkins plugins before. Client
side extension points can help isolate failure, so one bad plugin doesn’t take
a whole page down.
Server Sent Events
To make Blue Ocean a success, we’re asking for help and support from Jenkins
developers and plugin authors. Please join in our Blue Ocean discussions on the
Jenkins Developer
mailing list and the #jenkins-ux IRC channel on Freenode!
![]()
↧
August 19, 2016, 12:42 pm
About me
My name is Samat Davletshin and I am from HSE University from Moscow, Russia. I
interned at Intel and Yandex, and cofounded a startup
project where I personally developed front-end and back-end of the website.
I am excited to participate in GSoC with Jenkins this summer as a chanсe to make
a positive change for thousands of users as well as to learn from great mentors.
Abstract
Although powerful, Jenkins new job creation and configuration process may be non
obvious and time consuming. This can be improved by making UI more intuitive,
concise, and functional. I plan to achieve this by creating a simpler new job
creation, configuration process focused on essential elements, and embedding new
functionality.
Deliverables
New job creation
Initially, job validation was unresponsive, job creation was still allowed with
an invalid name, and some allowed characters even crashed Jenkins. Happily, two
of this problems were fixed in recent improvements and I plan add only a real
time name check for invalid characters.
Jenkins has a lot of windows reloads that may time consuming. The creation of
new job is a simple process requiring only job name and job type. This way UI
may be improved by reducing page reloads and putting new job creation interface
in a dialog window. Such popup would likely consist of three steps of
implementation: rendering a dialog window, receiving JSON with job types,
sending a POST request to create the job.
Configuration page
Changing help information
As reported by some users, it would be useful to have the functionality to
change help information. Installation administrators would be able to change the
help info and choose editing rights for other users. That would likely require a
creation of extension points and a plugin using them. I also would like to
include the ability to style the help information using markdown as shown above.
[Optional] The functionality is extended to creation of crowd sourced "wiki like" documentation
As inlocalization
plugin the changes are gathered and applied beyond installation of a particular
user.
More intuitive configuration page.
Although there are a lot improvements in new configuration page, there is always
a room for improvements. An advanced job still has a very complicated and hard
to read configuration page. It is still open to discussion, but I may approach
it by better division of configuration parts such as an accordion based
navigation.
Home page
[Optional] Removing "My Views" page
"My Views" page may unnecessary complicate essential sidepanel navigation. Since
it contains very small functionality, the functions may be moved to the home
page and the whole page may be removed. That may be implemented by adding icons
to "My Views" tabs. Additionally, the standard view creation page can create
either of the types
[Optional] Reducing number of UI elements
The home page may contain some UI elements that are not essential and rarely
used. This way elements "enable auto refresh", “edit description”, “icon sizes”,
”legend”, “RSS” may be removed from home page and placed under "Manage Jenkins"
or an upper menu. It is also possible to create new extension points to support
new UI elements through plugins.
Credentials store page
[Optional] Grouping credentials and their domains
Credentials page has too many reloads and requires many clicks to get to a
required credentials page. That may be improved by removing the last page and
showing credentials under domains.
Current progress
By May 25th I learned about the structure and tools of Jenkins and started
working on the first project:
I started with New Job Name validation first. Luckily, in last updates thechanges of recena there
were implemented all of the changes I proposed except real time check on name
validity. Here I proposed the change which fixes it by
sending GET request on keyup event in addition to blur.
I also made a New Job Popup with using existing interface.
I used Remodal library for popup and put
thereexisting
New Job container. Surprisingly, it was fully functional right away. On the GIF
you can see that popup receives all job types and then successfully submits the
post form creating a new job. I think that could be a good first step. Further I
can start changing the window itself.
![]()
↧
↧
August 19, 2016, 12:42 pm
Those of you updating the Pipeline Groovy plugin
to 2.3 or later will notice a change to the appearance of the configuration form.
The Snippet Generator tool is no longer a checkbox enabled inside the configuration page.
Rather, there is a link Pipeline Syntax which opens a separate page with several options.
(The link appears in the project’s sidebar; Jenkins 2 users will not see the sidebar from the configuration screen,
so as of 2.4 there is also a link beneath the Pipeline definition.)
Snippet Generator continues to be available for learning the available
Pipeline steps and creating sample calls given various configuration options.
The new page also offers clearer links to static reference documentation, online
Pipeline documentation resources, and an IntelliJ IDEA code completion file
(Eclipse support is unfinished).
One motivation for this change
(JENKINS-31831) was to
give these resources more visual space and more prominence. But another
consideration was that people using multibranch projects or organization folders
should be able to use Snippet Generator when setting up the project, before
any code is committed.
Those usingPipeline
Multibranch plugin or organization folder plugins should upgrade to 2.4 or
later to see these improvements as well.
![]()
↧
August 19, 2016, 12:42 pm
About me
I am Cynthia Anyango from Nairobi, Kenya. I am a second year student at Maseno
University. I am currently specializing on Ruby on Rails and trying to learn
Python. I recently started contributing to Open source projects.My major
contribution was at Mozilla, where I worked with the QA for Cloud services. I did
manual and automated tests for various cloud services. I wrote documentation
too. Above that, I am competent and I am always passionate about what I get my
hands on.
Project summary
Currently Jenkins plugin documentation is being stored in Confluence. Sometimes
the documentation is scattered and outdated. In order to improve the situation we
would like to follow the documentation-as-code approach and to put docs to
plugin repositories and then publish them on the project website using the
awestruct engine. The project aims an implementation of a documentation
continuous deployment flow powered by Jenkins and Pipeline Plugin.
The idea is to automatically pull in the README and other docs from GitHub, show
changelogs with versions and releases dates. I will be designing file templates
that will contain most of the docs information that will be required from
plugin developers. Initially the files will be written inAsciiDoc. Plugin developers will get a chance to
review the templates. The templates will be prototyped by various plugin
developers.
The docs that will be automatically pulled from github and will be published onJenkins.io under the Documentation section.
I hope to achieve this by 25th June when we will be having our mid-term
evaluations.
I will update more on the progress.
![]()
↧
August 19, 2016, 12:42 pm
Earlier this year, we published a case study on howLyft has used Amazon EC2 Spot instances to save 75% on their continuous delivery
infrastructure costs by simply changing four lines of code. Several other EC2 customers like Mozilla have
also reduced costs of their
continuous integration, deployment and testing pipelines by up to 90% on Spot instances. You can view
the current savings on Spot instances over EC2 On-demand instances using theSpot Bid Advisor:
AWS Spot instances are spare EC2 instances that you can bid on. While your Spot instances may be
terminated when EC2’s spare capacity declines, you can automatically replenish these instances and
maintain your target capacity using
EC2 Spot fleets. As each
instance type and Availability Zone provides an alternative capacity pool, you can select multiple
such pools to launch the lowest priced instances currently available by launching a Spot
fleet on the Amazon EC2 Spot Requests console
or using the AWS CLI/SDK tools.
In this walkthrough, we’ll show you how to configure Jenkins to automatically scale a fleet of Spot
instances up or down depending on the number jobs to be completed.
Request an Amazon EC2 Spot fleet
To get started, login to Amazon EC2 console, and click on Spot Requests
in the left hand navigation pane. Alternatively, you can directly login toAmazon EC2 Spot Requests console. Then click on theRequest Spot Instances button at the top of the dashboard.
In the Spot instance launch wizard, select the Request & Maintain option to request a Spot fleet that automatically
provisions the most cost-effective EC2 Spot instances, and replenishes them if interrupted. Enter an initial
target capacity, choose an AMI, and select multiple instance types to automatically provision the lowest priced
instances available.
On the next page, ensure that you have selected a key pair, complete the launch wizard, and note the Spot
fleet request ID.
Amazon EC2 Spot fleet automates finding the lowest priced instances for you, and enables your Jenkins cluster
to maintain the required capacity; so, you don’t need any bidding algorithms to provision the optimal Spot
instances over time.
Install the Plugin
From the Jenkins dashboard, select Manage Jenkins, and then click Manage Plugins. On the Available tab,
search for and select the EC2 Fleet Jenkins Plugin. Then click the Install button.
After the plugin installation is completed, select Manage Jenkins from the Jenkins dashboard, and
click Configure System. In the Cloud section, select Amazon Spot Fleet to add a new Cloud.
Next, we will configure the AWS and slave node credentials. Click the Add button next to AWS Credentials,
select Jenkins, and enter your AWS Access Key, secret, and ID.
Next, click the Add button in the Spot fleet launcher to configure your slave agents with an SSH key.
Select Jenkins, and enter the username and private key (from the key pair you configured in your Spot fleet request)
as shown below.
Confirm that the AWS and SSH credentials you just added are selected. Then choose the region, and the Spot fleet
request ID from the drop-down. You can also enter the maximum idle time before your cluster automatically scales
down, and the maximum cluster size that it can scale up to.
Submit Jobs and View Status
After you have finished the previous step, you can view the EC2 Fleet Status in the left hand navigation pane on
the Jenkins dashboard. Now, as you submit more jobs, Jenkins will automatically scale your Spot fleet to add more
nodes. You can view these new nodes executing jobs under the Build Executor Status.
After the jobs are done, if the nodes remain free for the specified idle time (configured in the previous step),
then Jenkins releases the nodes, automatically scaling down your Spot fleet nodes.
Build faster and cheaper
If you have a story to share about your team or product, or have a question to ask, do leave a comment
for us; we’d love to connect with you!
![]()
↧
August 19, 2016, 12:42 pm
It is hard to believe that the first half of 2016 is almost over and summer is
just around the corner. As usual, there are plenty of educational Jenkins
events planned for this month. Below lists what’s happening in your neck of the
woods:
![]()
↧
↧
August 19, 2016, 12:42 pm
About myself
Hello, my name is Payal Priyadarshini. I am pursing my major in Computer
Science & Engineering at the Indian Institute of Technology Kharagpur, India. I
am very proficient in writing code in Python, C++, Java and currently getting
familiar and hopefully good in Groovy too.
I have internship experiences in renowned institutions like Google and VMware
where I worked with some exciting technologies for example Knowledge Graphs,
BigTable, SPARQL, RDF in Google. I am a passionate computer science student who
is always interested in learning and looking for new challenges and
technologies.That’s how I came across to Google Summer of Code where I am
working on some exciting data mining problems which you are going to encounter
below in this blog.
Project Overview
Jenkins has collected anonymous usage information of more than 100,000
installations which includes set of plugins and their versions etc and also
release history information of the upgrades. This data collection can be used
for various data mining experiments. The main goal of this project is to perform
various analysis and studies over the available dataset to discover trends
in data usage. This project will help us to learn more about the Jenkins
usage by solving various problems, such as:
Plugin versions installation trends, will let us know about the versions installation behaviour of a given plugin.
Spotting downgrades, which will warn us that something is wrong with the version from which downgrading was performed.
Correlating what users are saying (community rating) with what users are doing (upgrades/downgrades).
Distribution of cluster size, where clusters represents jobs, nodes count which approximates the size of installation.
Finding set of plugins which are likely to be used together, will setup pillar for plugin recommendation system.
As a part of the Google Summer of Code 2016, I will be working on the above
mentioned problems. My mentors for the project are Kohsuke Kawaguchi and Daniel Beck. Some analyses has already been done over this
data but those are outdated as charts can be more clearer and interactive. This project aims to improvise existing
statistics and generating new ones discussed above.
Use Cases
This project covers wide-range of the use-cases that has been derived from the
problems mentioned above.
Use Case 1: Upgrade/Downgrade Analysis
Understanding the trend in upgrades and downgrades have lots of utilities, some
of them have already been explained earlier which includes measuring the
popularity, spotting downgrades, giving warning about the wrong versions quickly
etc.
Use Case 1.1: Plugin versions installation trends
Here we are analysing the trend in the different version installations for a
given plugin. This use-case will help us to know about:
Trend in the upgrade to the latest version released for a given plugin.
Trend in the popularity decrement of the previous versions after new version release.
Find the most popular plugin version at any given point of time.
Use Case 1.2: Spotting dowgrades
Here we are interested to know, how many installations are downgraded from any
given version to previously used version. Far fetched goal of this analysis is
to give warning when something goes wrong with the new version release, which
can be sensed using downgrades performed by users. This analysis can be
accomplished by studying the monotonic property of the version number vs.
timestamp graph for a given plugin.
Use Case 1.3: Correlation with the perceived quality of Jenkins release
To correlate what users are saying to what users are doing, we have community
ratings which tells us about the ratings and reviews of the releases and has
following parameters:
Used the release on production site w/o major issues.
Don’t recommend to other.
Tried but rolled it back to the previous version.
First parameters can be calculated from the Jenkins usage data and third
parameter is basically spotting downgrades(use case 1.2). But the second
parameter is basically an expression which is not possible to calculate. This
analysis is just to get a subjective idea about the correlation.
Use Case 2: Plugin Recommendation System
This section involves setting up ground work for the plugin recommendation
system. The idea is to find out the set of plugins which are most likely to be
used together. Here we will be following both content based filtering as well as
collaborative filtering approach.
This approach is based upon analysing large amount of information on
installation’s behaviours and activities. We have implicit form of the data
about the plugins, that is for every install ids, we know the set of plugins
installed. We can use this information to construct plugin usage graph where
nodes are the plugins and the edges between them is the number of installations
in which both plugins are installed together.
This method is based on a properties or the content of the item for example
recommending items that are similar to the those that a user liked in the past
or examining in the present based upon some properties. Here, we are utilizingJenkins
plugin dependency graph to learn about the properties of a plugin. This graph
tells us about dependent plugins on a given plugin as well as its dependencies
on others. Here is an example to show, how this graph is use for content based
filetring, suppose if a user is using “CloudBees Cloud Connector”, then we can
recommend them for “CloudBees Registration Plugin” as both plugins are dependent
on “CloudBees Credentials Plugin”.
Additional Details
You may find the complete project proposal along with the detailed design of the
use-cases with their implementation details here in thedesign
document.
A complete version of the use-case 1: Upgrade & Downgrade Analysis should be
available in late June and basic version of plugin recommendation system will be
available in late July.
![]()
↧
August 19, 2016, 12:42 pm
About me
I am Minudika Malshan, an undergraduate student in Computer Science and Engineering from University of Moratuwa, Sri Lanka.
As a person who is passionate in open source software development and seeking for new knowledge and experience, I am willing to give my contribution for this project.
Abstract
The Support-Core Plugin provides the basic infrastructure for generating "bundles" of support information with Jenkins.
There are two kinds of bundles.
Automatic bundles: Bundles which are generated and get saved in $JENKINS_HOME/support once per hour starting 15 seconds after Jenkins starts the plugin.
The automatic bundles are retained using an exponential aging strategy. Therefore it’s possible to have a bunch of them over the entire lifetime after the plugin installing the plugin.
On demand bundles: These bundles are generated from the root "Support" action.
However current support-core plugin is not much user friendly. The object of this project is to make it more user friendly by adding some features which make a sophisticated environment for the user who use support plugin.
In this project scope, there are three features and improvements we are going to consider.
Ease the bundles management by the administrator (JENKINS-33090)
Adding an option to anonymize customer labels (strings created by the user such as name of a job, folder, view, slave, and template etc). (JENKINS-33091)
Allowing user to create an issue and submit a bundle into the OSS tracker using the support-core plugin. (JENKINS-21670)
Tasks and Deliverables
Ease the bundles management by the administrator.
Under this task, the following functions are going to be implemented.
Listing bundles stored on the jenkins instance with their details.
Allowing user to download each bundle.
Allowing user to delete each bundle or all bundles.
Allowing user to browse the content of each bundle.
Automatically purging old bundles.
Enabling user to create an issue and submit a bundle into the OSS tracker
When a Jenkins user sees an issue, he/she commonly contacts his support contacts (Jenkins instance admins) and then Jenkins admins troubleshoot the issue.
The objective of this task is to implement a feature which enables the user to report an issue to a admin through support core plugin.
When creating bundles to attach with the ticket, it is important to protect the privacy of the user who creates the ticket. When considering doing that, anonymizing user created labels (texts) comes to the front.
Adding an option to anonymize customer labels
The following functions will be implemented under this taks.
Creating randomized tokens for labels created by users.
Producing a mapping for those labels.
Substituting encoded labels into all the files included in the support bundle.
When creating randomized tokens, it would be much useful and effective if we can create those tokens in a way they make sense to humans. (i.e. readable to humans). For that, I am hoping to use a suitable java library to create human friendly random tokens. One of such libraries is wordnet-random-name.
However in order to substitute randomized tokens, all files included in the bundle should be read. This can become inefficient when bundle consists of large number of files. Therefore it’s important to follow an optimized method for this task.
![]()
↧
August 19, 2016, 12:42 pm
Join us in Santa Clara, California on September 13-15, 2016!
We are excited to announce the Jenkins
World agenda is now live. There will be 50+ sessions, keynotes, training,
certifications and workshops. Here are a few highlights of what you can expect:
High level topics
Additionally, Jenkins World offers great opportunities for hands-on learning,
exploring and networking:
Plugin Development Workshop
Due to its popularity in previous years, we are bringing back the plugin
development workshop. This workshop will introduce developers to the Jenkins
plugin ecosystem and terminology. The goal is to provide a cursory overview of
the resources available to Jenkins plugin developers. Armed with this
information, Jenkins developers can learn how to navigate the project and
codebase to find answers to their questions.
Birds of a Feather Sessions
BoFs, as they are usually known, will be a new addition to Jenkins World this
year. Sessions will be curated on various technical topics from DevOps to how
enterprises are integrating Jenkins in their environment. Discussions will be
lead by the industry’s brightest minds who have an influence in shaping the
future of Jenkins.
Ask the Experts
Got a Jenkins question that’s been keeping you up at night? Need to bounce ideas
off somebody? Or you just need someone to fix your Jenkins issue? This is your chance
to get connected with the Jenkins Experts. Experts will be on hand to help with
all your Jenkins needs on Sept 14th & 15th.
Prepare for Jenkins Certification
The objective of this session is to help you assess your level of readiness for
the certification exam - either the Certified Jenkins Engineer (CJE/open source)
certification or the Certified CloudBees Jenkins Platform Engineer
(CCJPE/CloudBees-specific) certification. After an overview about the
certification program, a Jenkins expert from CloudBees will walk you through the
various sections of the exam, highlighting the important things to master ahead
of time, not only from a pure knowledge perspective but also in terms of
practical experience. This will be an interactive session.
![]()
↧
August 19, 2016, 12:42 pm
Implementing a CI/CD solution based on Jenkins has become very easy. Dealing
with hundreds of jobs? Not so much. Having to scale to thousands of jobs?
Now this is a real challenge.
This is the story of a journey to get out of the jungle of jobs…
Start of the journey
At the beginning of the journey there were several projects using roughly the same
technologies. Those projects had several
branches, for maintenance of releases, for new features.
In turn, each of those branches had to be carefully built, deployed on different
platforms and versions, promoted so they could be tested for functionalities,
performances and security, and then promoted again for actual delivery.
Additionally, we had to offer the test teams the means to deploy any version of
their choice on any supported platform in order to carry out some manual tests.
This represented, for each branch, around 20 jobs. Multiply this by the number of
branches and projects, and there you are: more than two years after the start
of the story, we had more than 3500 jobs.
3500 jobs. Half a dozen people to manage them all…
Preparing the journey
How did we deal with this load?
We were lucky enough to have several assets:
time - we had time to design a solution before the scaling went really out of
control
forecast - we knew that the scaling would occur and we were not taken by
surprise
tooling - the Jenkins Job DSL
was available, efficient and well documented
We also knew that, in order to scale, we’d have to provide a solution with the
following characteristics:
self-service - we could not have a team of 6 people become a bottleneck for
enabling CI/CD in projects
security - the solution had to be secure enough in order for it to be used by
remote developers we never met and didn’t know
simplicity - enabling CI/CD had to be simple so that people having
never heard of it could still use it
extensibility - no solution is a one-size-fits-all and must be flexible
enough to allow for corner cases
Creating pipelines using the Job DSL and embedding the scripts in the code was
simple enough. But what about branching? We needed a mechanism to allow the
creation of pipelines per branch, by downloading the associated DSL and to
run it in a dedicated folder.
But then, all those projects, all those branches, they were mostly using the
same pipelines, give or take a few configurable items. Going this way would
have lead to a terrible duplication of code, transforming a job maintenance
nightmare into a code maintenance nightmare.
Pipeline as configuration
Our trick was to transform this vision of "pipeline as code" into a "pipeline
as configuration":
by maintaining well documented and tested "pipeline libraries"
by asking projects to describe their pipeline not as code, but as property
files which would:
define the name and version of the DSL pipeline library to use
use the rest of the property file to configure the pipeline library, using
as many sensible default values as possible
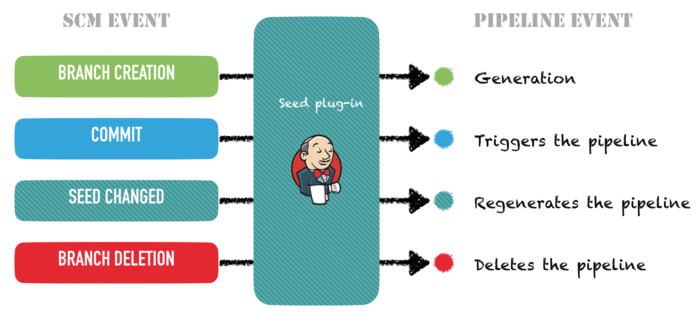
Piloting the pipeline from the SCM
Once this was done, the only remaining trick was to automate the creation,
update, start and deletion of the pipelines using SCM events. By enabling SCM
hooks (in GitHub, BitBucket or even in Subversion), we could:
automatically create a pipeline for a new branch
regenerate a pipeline when the branch’s pipeline description was modified
start the pipeline on any other commit on the branch
remove the pipeline when the branch was deleted
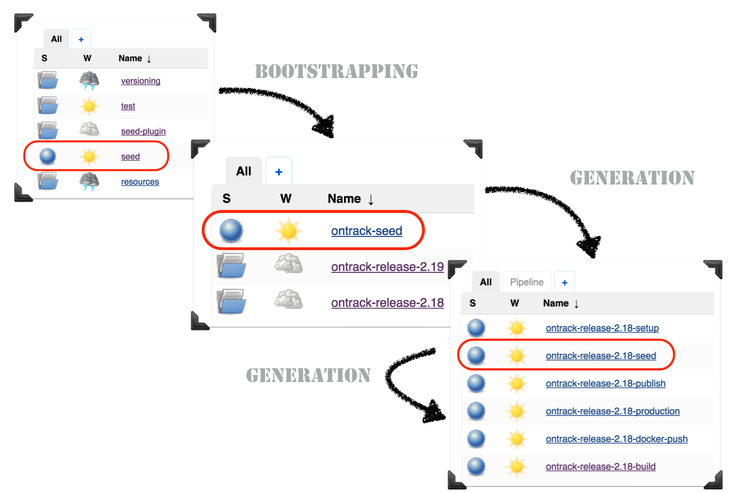
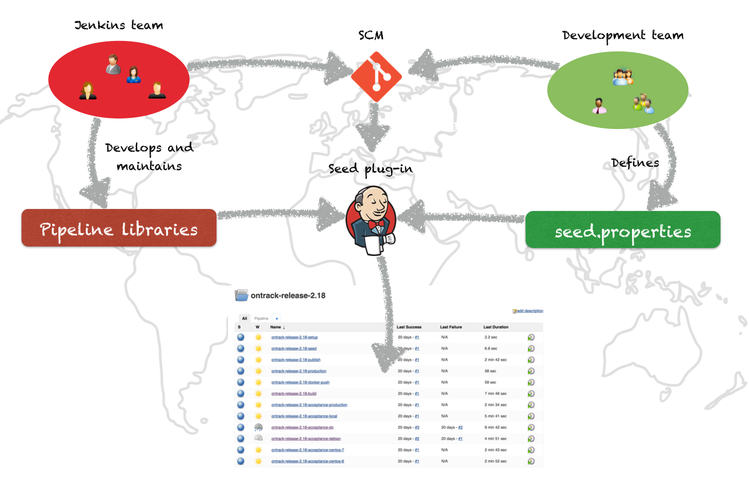
Once a project wants to go in our ecosystem, the Jenkins team "seeds" the
project into Jenkins, by running a job and giving a few parameters.
It will create a folder for the project and grant proper authorisations, using
Active Directory group names based on the project name.
The hook for the project must be registered into the SCM and you’re up and
running.
Configuration and code
Mixing the use of strong pipeline libraries configured by properties and the
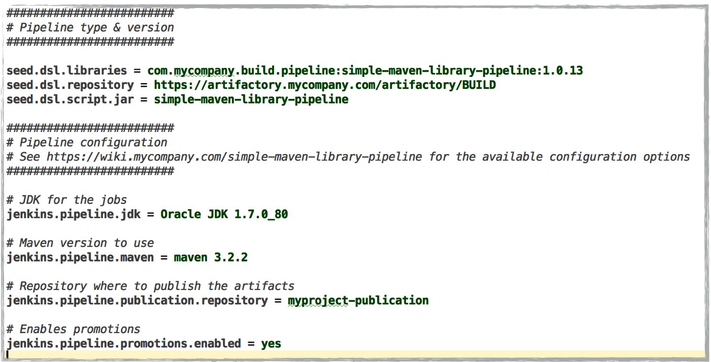
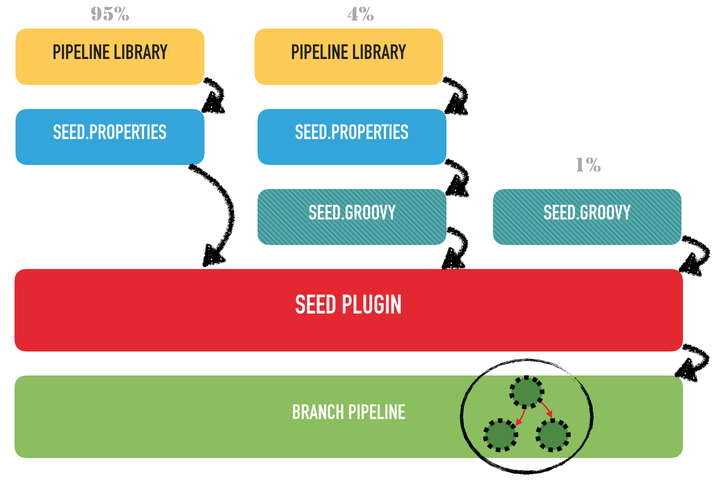
direct use of the Jenkins Job DSL is still possible. The Seed plugin
supports all kinds of combinations:
use of pipeline libraries only - this can even be enforced
use a DSL script which can in turn use some classes and methods defined in
a pipeline library
use of a Job DSL script only
Usually, we tried to have a maximum reuse, through only pipeline libraries, for
most of our projects, but in other circumstances, we were less strict and
allowed some teams to develop their own pipeline script.
End of the journey
In the end, what did we achieve?
Seed and Pipeline plugin
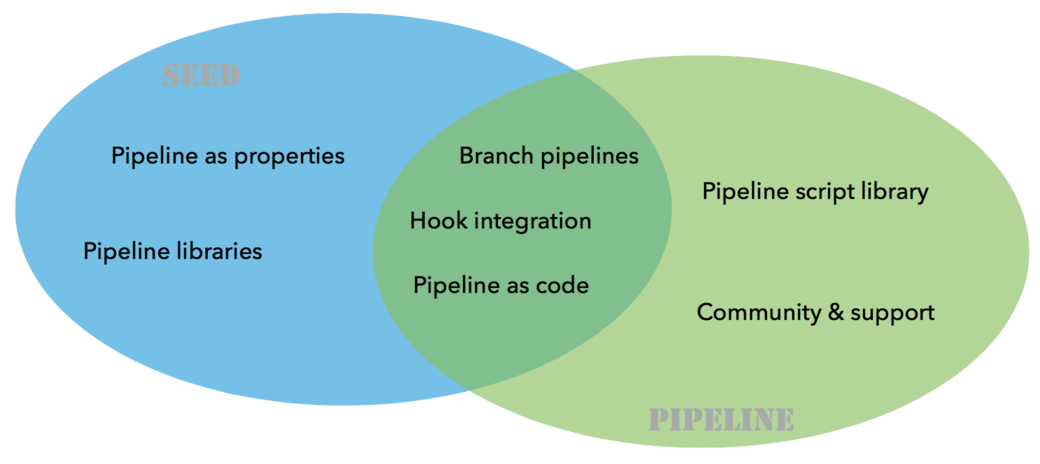
Now, what about the Pipeline plugin? Both
this plugin and the Seed plugin have common functionalities:
What we have found in our journey is that having a "pipeline as configuration"
was the easiest and most secure way to get a lot of projects on board, with
developers not knowing Jenkins and even less the DSL.
The outcome of the two plugins is different:
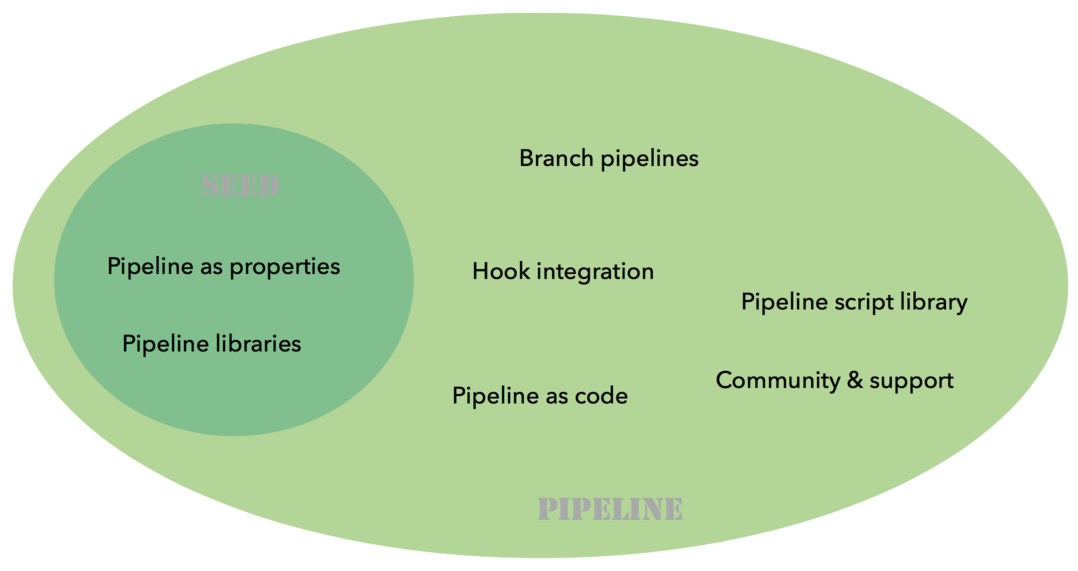
If time allows, it would be probably a good idea to find a way to integrate the
functionalities of the Seed plugin into the pipeline framework, and to keep
what makes the strength of the Seed plugin:
Links
You can find additional information about the Seed plugin and its usage at the
following links:
![]()
↧
↧
August 19, 2016, 12:42 pm
|
This is a guest post by Liam Newman,
Technical Evangelist at Cloudbees. |
So much to do, so little time…
Every time I’ve moved a team to continuous integration and delivery, one problem
we always encounter is how to run all the tests needed to ensure high-quality
changes while still keeping pipeline times reasonable and changes flowing
smoothly. More tests mean greater confidence, but also longer wait times.
Build systems may or may not support running tests in parallel but only on one
machine even while other lab machines sit idle. In these cases, parallelizing
test execution across multiple machines is a great way to speed up pipelines.
The Parallel Test Executor plugin lets us leverage Jenkins do just that with no
disruption to the rest of the build system.
Serial Test Execution
For this post, I’ll be running a pipeline based on the
Jenkins Git Plugin. I’ve modified
the Jenkinsfile from that project to allow us to compare execution times to our
later changes, and I’ve truncated the "mvn" utility method since it remains
unchanged. You can find the original file
here.
node {
stage 'Checkout'
checkout scm
stage 'Build'/* Call the Maven build without tests. */
mvn "clean install -DskipTests"
stage 'Test'
runTests()/* Save Results. */
stage 'Results'/* Archive the build artifacts */
archive includes: 'target/*.hpi,target/*.jpi'
}void runTests(def args) {/* Call the Maven build with tests. */
mvn "install -Dmaven.test.failure.ignore=true"/* Archive the test results */
step([$class: 'JUnitResultArchiver', testResults: '**/target/surefire-reports/TEST-*.xml'])
}/* Run Maven */void mvn(def args) { /* ... */ }
| This pipeline expects to be run from a Jenkinsfile in SCM.
To copy and paste it directly into a Jenkins Pipeline job, replace the checkout scm step withgit 'https://github.com/jenkinsci/git-plugin.git'. |
It’s a Maven project, so the Jenkinsfile is pretty simple.
As noted above, I’ve split the Maven build into separate “Build” and “Test”
stages. Maven doesn’t support this split very well, it wants to run its all
the steps of the lifecycle in order every time. So, I have to call Maven twice:
first using the “skipTests” property to do only build steps in the first call,
and then a second time with out that property to run tests.
On my quad-core machine, executing this pipeline takes about 13 minutes and 30
seconds. Of that time, it takes 13 minutes to run about 2.7 thousand tests in
serial.
Parallel Test Execution
This looks like an ideal project for parallel test execution. A short build
followed by a large number of serially executed tests that consume the most of
the pipeline time. There are a number of things I could try to optimize this.
For example, I could modify test harness to look for ways to parallelize
the test execution on this single machine. Or I could try speed up the tests
themselves. Both of those can be time-consuming and both risk destablizing the
tests. I’d need to know more about the project to do it well.
I’ll avoid that risk by using Jenkins and the
Parallel Test Executor Plugin to
parallelize the tests across multiple nodes instead. This will isolate the tests
from each other, while still giving us speed gains from parallel execution.
The plugin will read the list of tests from the results archived in the previous execution of this
job and splits that list into the specified number of sublists. I can then use
those sublists to execute the tests in parallel, passing a different sublist to
each node.
Let’s look at how this changes the pipeline:
node { /* ...unchanged... */ }void runTests(def args) {/* Request the test groupings. Based on previous test results. *//* see https://wiki.jenkins-ci.org/display/JENKINS/Parallel+Test+Executor+Plugin and demo on github
/* Using arbitrary parallelism of 4 and "generateInclusions" feature added in v1.8. */def splits = splitTests parallelism: [$class: 'CountDrivenParallelism', size: 4], generateInclusions: true/* Create dictionary to hold set of parallel test executions. */def testGroups = [:]for (int i = 0; i < splits.size(); i++) {def split = splits[i]/* Loop over each record in splits to prepare the testGroups that we'll run in parallel. *//* Split records returned from splitTests contain { includes: boolean, list: List<String> }. *//* includes = whether list specifies tests to include (true) or tests to exclude (false). *//* list = list of tests for inclusion or exclusion. *//* The list of inclusions is constructed based on results gathered from *//* the previous successfully completed job. One additional record will exclude *//* all known tests to run any tests not seen during the previous run. */
testGroups["split-${i}"] = { // example, "split3"
node {
checkout scm/* Clean each test node to start. */
mvn 'clean'def mavenInstall = 'install -DMaven.test.failure.ignore=true'/* Write includesFile or excludesFile for tests. Split record provided by splitTests. *//* Tell Maven to read the appropriate file. */if (split.includes) {
writeFile file: "target/parallel-test-includes-${i}.txt", text: split.list.join("\n")
mavenInstall += " -Dsurefire.includesFile=target/parallel-test-includes-${i}.txt"
} else {
writeFile file: "target/parallel-test-excludes-${i}.txt", text: split.list.join("\n")
mavenInstall += " -Dsurefire.excludesFile=target/parallel-test-excludes-${i}.txt"
}/* Call the Maven build with tests. */
mvn mavenInstall/* Archive the test results */
step([$class: 'JUnitResultArchiver', testResults: '**/target/surefire-reports/TEST-*.xml'])
}
}
}
parallel testGroups
}/* Run Maven */void mvn(def args) { /* ... */ }
That’s it! The change is significant but it is all encapsulated in this one
method in the Jenkinsfile.
Great (ish) Success!
Here’s the results for the new pipeline with parallel test execution:
The tests ran almost twice as fast, without changes outside pipeline. Great!
However, I used 4 test executors, so why am I not seeing a 4x? improvement.
A quick review of the logs shows the problem: A small number of tests are taking up
to 5 minutes each to complete! This is actually good news. It means that I
should be able to see further improvement in pipeline throughput just by refactoring
those few long running tests into smaller parts.
Conclusion
While I would like to have seen closer to a 4x improvement to match to number
of executors, 2x is still perfectly respectable. If I were working on a group of projects
with similar pipelines, I’d be completely comfortable reusing these same changes
on my other project and I’d expect to similar improvement without any disruption to
other tools or processes.
![]()
↧
August 19, 2016, 12:42 pm
On this week GSoC students are going to present their projects as a part of mid-term evaluation,
which covers one month of community bonding and one month of coding.
We would like to invite Jenkins developers to attend these meetings.
There are two additional months of coding ahead for successful students, so any feedback from Jenkins contributors and users will be appreciated.
Both meetings will be conducted and recorded via Hangouts on Air.
The recorded sessions will be made public after the meetup.
The agenda may change a bit.
![]()
↧
August 19, 2016, 12:42 pm
| This is a guest post by R. Tyler Croy, who is a
long-time contributor to Jenkins and the primary contact for Jenkins project
infrastructure. He is also a Jenkins Evangelist atCloudBees, Inc. |
For ages I have used the "Build After" feature in Jenkins to cobble together
what one might refer to as a "pipeline" of sorts. The Jenkins project itself, a
major consumer of Jenkins, has used these daisy-chained Freestyle jobs to drive
a myriad of delivery pipelines in our infrastructure.
One such "pipeline" helped drive the complex process of generating the pretty
blue charts onstats.jenkins-ci.org.
This statistics generation process primarily performs two major tasks, on rather
large sets of data:
Generate aggregate monthly "census data."
Process the census data and create trend charts
The chained jobs allowed us to resume the independent stages of the pipeline,
and allowed us to run different stages on different hardware (different
capabilities) as needed. Below is a diagram of what this looked like:
The infra_generate_monthly_json would run periodically creating the
aggregated census data, which would then be picked up by infra_census_push
whose sole responsibility was to take census data and publish it to the
necessary hosts inside the project’s infrastructure.
The second, semi-independent, "pipeline" would also run periodically. Theinfra_statistics job’s responsibility was to use the census data, pushed
earlier by infra_census_push, to generate the myriad of pretty blue charts
before triggering theinfra_checkout_stats job which would make sure stats.jenkins-ci.org was
properly updated.
Suffice it to say, this "pipeline" had grown organically over a period time whenmore advanced tools weren’t quite available.
When we migrated to newer infrastructure forci.jenkins.io earlier this year I took the
opportunity to do some cleaning up. Instead of migrating jobs verbatim, I pruned
stale jobs and refactored a number of others into properPipelines, statistics generation being an obvious
target!
Our requirements for statistics generation, in their most basic form, are:
Enable a sequence of dependent tasks to be executed as a logical group (a
pipeline)
Enable executing those dependent tasks on various pieces of infrastructure
which support different requirements
Actually generate those pretty blue charts
| If you wish to skip ahead, you can jump straight to theJenkinsfile
which implements our new Pipeline. |
The first iteration of the Jenkinsfile simply defined the conceptual stages we
would need:
node {
stage 'Sync raw data and census files'
stage 'Process raw logs'
stage 'Generate census data'
stage 'Generate stats'
stage 'Publish census'
stage 'Publish stats'
}
How exciting! Although not terrifically useful. When I began actually
implementing the first couple stages, I noticed that the Pipeline might syncdozens of gigabytes of data every time it ran on a new agent in the cluster.
While this problem will soon be solved by theExternal
Workspace Manager plugin, which is currently being developed. Until it’s ready,
I chose to mitigate the issue by pinning the execution to a consistent agent.
/* `census` is a node label for a single machine, ideally, which will be
* consistently used for processing usage statistics and generating census data
*/
node('census && docker') {/* .. */
}
Restricting a workload which previously used multiple agents to a single one
introduced the next challenge. As an infrastructure administrator, technically
speaking, I could just install all the system dependencies that I want on this
one special Jenkins agent. But what kind of example would that be setting!
The statistics generation process requires:
Tool Auto-Installers are exposed in Pipeline through the tool step and onci.jenkins.io we already had JDK8 and Groovy
available. This meant that the Jenkinsfile would invoke tool and Pipeline
would automatically install the desired tool on the agent executing the current
Pipeline steps.
The tool step does not modify the PATH environment variable, so it’s usually
used in conjunction with the withEnv step, for example:
node('census && docker') {/* .. */def javaHome = tool(name: 'jdk8')def groovyHome = tool(name: 'groovy')/* Set up environment variables for re-using our auto-installed tools */def customEnv = ["PATH+JDK=${javaHome}/bin","PATH+GROOVY=${groovyHome}/bin","JAVA_HOME=${javaHome}",
]/* use our auto-installed tools */
withEnv(customEnv) {
sh 'java --version'
}/* .. */
}
CloudBees Docker Pipeline plugin
Satisfying the MongoDB dependency would still be tricky. If I caved in and installed
MongoDB on a single unicorn agent in the cluster, what could I say the next time
somebody asked for a special, one-off, piece of software installed on our
Jenkins build agents?
After doing my usual complaining and whining, I discovered that the CloudBees
Docker Pipeline plugin provides the ability to run containers inside of aJenkinsfile. To make things even better, there areofficial MongoDB docker images readily
available on DockerHub!
This feature requires that the machine has a running Docker daemon which is
accessible to the user running the Jenkins agent. After that, running a
container in the background is easy, for example:
node('census && docker') {/* .. *//* Run MongoDB in the background, mapping its port 27017 to our host's port
* 27017 so our script can talk to it, then execute our Groovy script with
* tools from our `customEnv`
*/
docker.image('mongo:2').withRun('-p 27017:27017') { container ->
withEnv(customEnv) {
sh "groovy parseUsage.groovy --logs ${usagestats_dir} --output ${census_dir} --incremental"
}
}/* .. */
}
The beauty, to me, of this example is that you can pass aclosure to withRun which will
execute while the container is running. When the closure is finished executin,
just the sh step in this case, the container is destroyed.
With that system requirement satisfied, the rest of the stages of the Pipeline
fell into place. We now have a single source of truth, theJenkinsfile,
for the sequence of dependent tasks which need to be executed, accounting for
variations in systems requirements, and it actually generatesthose pretty
blue charts!
Of course, a nice added bonus is the beautiful visualization of ournew Pipeline!
![]()
↧
August 19, 2016, 12:42 pm
Currently it’s quite difficult to share and reuse the same workspace between multiple jobs and across nodes.
There are some possible workarounds for achieving this, but each of them has its own drawback,
e.g. stash/unstash pre-made artifacts, Copy Artifacts plugin or advanced job settings.
A viable solution for this problem is the External Workspace Manager plugin, which facilitates workspace share and
reuse across multiple Jenkins jobs and nodes.
It also eliminates the need to copy, archive or move files.
You can learn more about the design and goals of the External Workspace Manager project in
this introductory blog post.
I’d like to announce that an alpha version of the External Manager Plugin has been released!
It’s now public available for testing.
To be able to install this plugin, you must follow the steps from the Experimental Plugins Update Center
blog post.
|
Please be aware that it’s not recommended to use the Experimental Update Center in production installations of
Jenkins, since it may break it.
|
The plugin’s wiki page may be accessed
here.
The documentation that helps you get started with this plugin may be found on theREADME page.
To get an idea of what this plugin does, which are the features implemented so far and to see a working demo of it,
you can watch my mid-term presentation that is available here.
The slides for the presentation are shared onGoogle Slides.
My mentors, Martin and Oleg,
and I have set up public meetings related to this plugin.
You are invited to join our discussions if you’d like to get more insight about the project.
The meetings are taking place twice a week on the Jenkins hangout,
every Monday at12 PM UTC
and every Thursday at5 PM UTC.
If you have any issues in setting up or using the plugin, please feel free to ask me on the plugin’s Gitter
chat.
The plugin is open-source, having the repository onGitHub, and you may contribute to it.
Any feedback is welcome, and you may provide it either on the Gitter chat, or onJira by using the external-workspace-manager-plugin component.
![]()
↧
↧
August 19, 2016, 12:42 pm
|
This is a guest post by Liam Newman,
Technical Evangelist at Cloudbees. |
Most projects need more that just JUnit result reporting. Rather than writing a
custom plugin for each type of report, we can use theHTML Publisher Plugin.
Let’s Make This Quick
I’ve found a Ruby project,
hermann, I’d like to build using Jenkins Pipeline. I’d
also like to have the code coverage results published with each build job. I could
write a plugin to publish this data, but I’m in a bit of hurry and
the build already creates an HTML report file using SimpleCov
when the unit tests run.
Simple Build
I’m going to use the
HTML Publisher Plugin
to add the HTML-formatted code coverage report to my builds. Here’s a simple
pipeline for building the hermann
project.
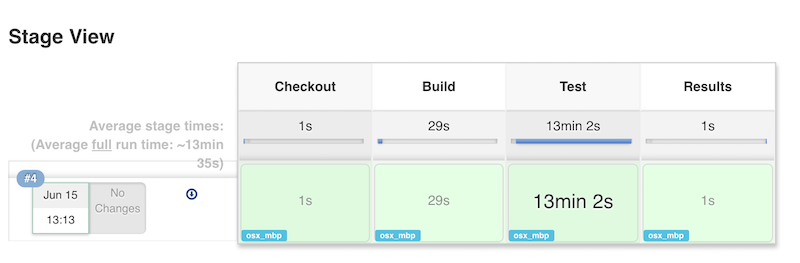
stage 'Build'
node {
// Checkout
checkout scm// install required bundles
sh 'bundle install'// build and run tests with coverage
sh 'bundle exec rake build spec'// Archive the built artifacts
archive (includes: 'pkg/*.gem')
}
| This pipeline expects to be run from a Jenkinsfile in SCM.
To copy and paste it directly into a Jenkins Pipeline job, replace the checkout scm step withgit 'https://github.com/reiseburo/hermann.git'. |
Simple enough, it builds, runs tests, and archives the package.
Now I just need to add the step to publish the code coverage report.
I know that rake spec creates an index.html file in the coverage directory.
I’ve already installed the
HTML Publisher Plugin.
How do I add the HTML publishing step to the pipeline? The plugin page doesn’t
say anything about it.
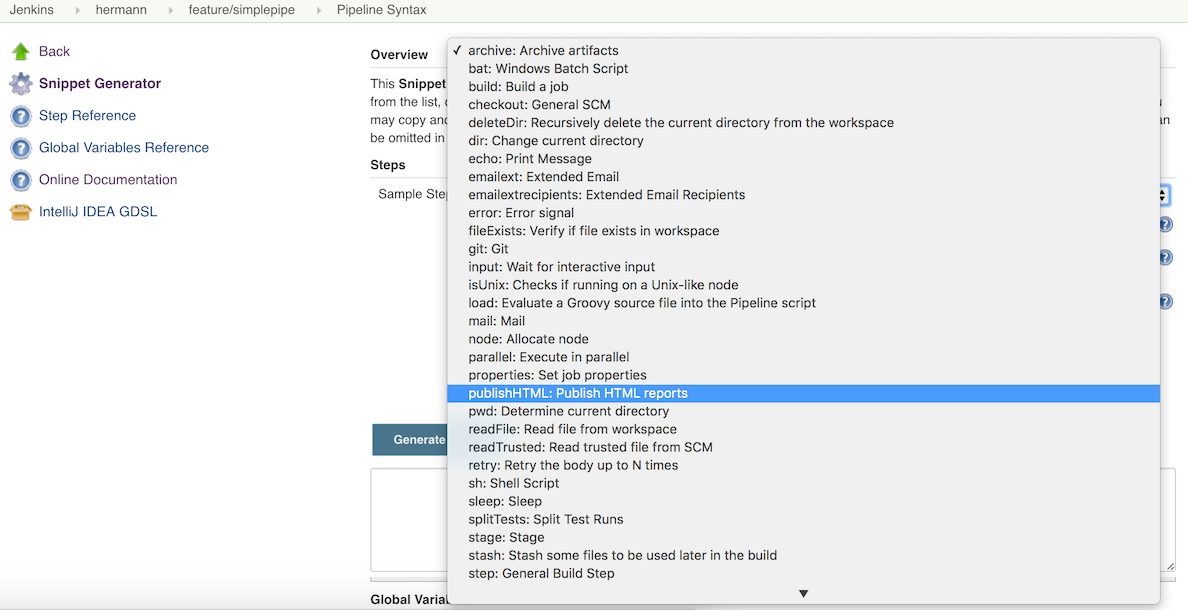
Snippet Generator to the Rescue
Documentation is hard to maintain and easy to miss, even more so in a system
like Jenkins with hundreds of plugins the each potential have one or more
groovy fixtures to add to the Pipeline. The Pipeline SyntaxSnippet Generator helps users
navigate this jungle by providing a way to generate a code snippet for any step using
provided inputs.
It offers a dynamically generated list of steps, based on the installed plugins.
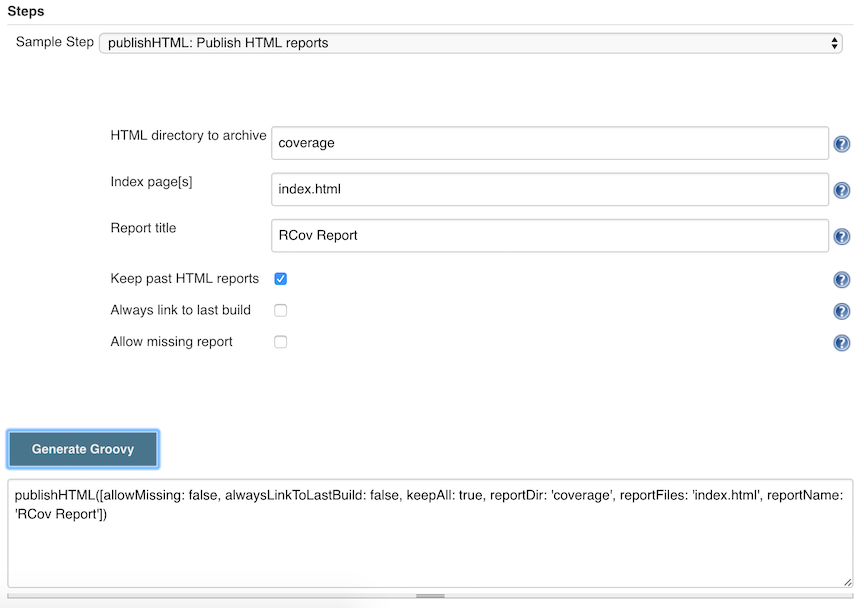
From that list I select the publishHTML step:
Then it shows me a UI similar to the one used in job configuration. I fill in
the fields, click "generate", and it shows me snippet of groovy generated from
that input.
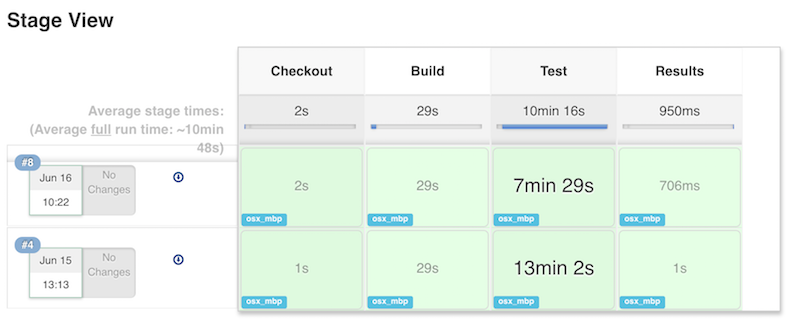
HTML Published
I can use that snippet directly or as a template for further customization.
In this case, I’ll just reformat and copy it in at the end of my
pipeline. (I ran into a minor bug
in the snippet generated for this plugin step. Typing
error string in my search bar immediately found the bug and a workaround.)
/* ...unchanged... */// Archive the built artifacts
archive (includes: 'pkg/*.gem')// publish html// snippet generator doesn't include "target:"// https://issues.jenkins-ci.org/browse/JENKINS-29711.
publishHTML (target: [allowMissing: false,alwaysLinkToLastBuild: false,keepAll: true,reportDir: 'coverage',reportFiles: 'index.html',reportName: "RCov Report"
])
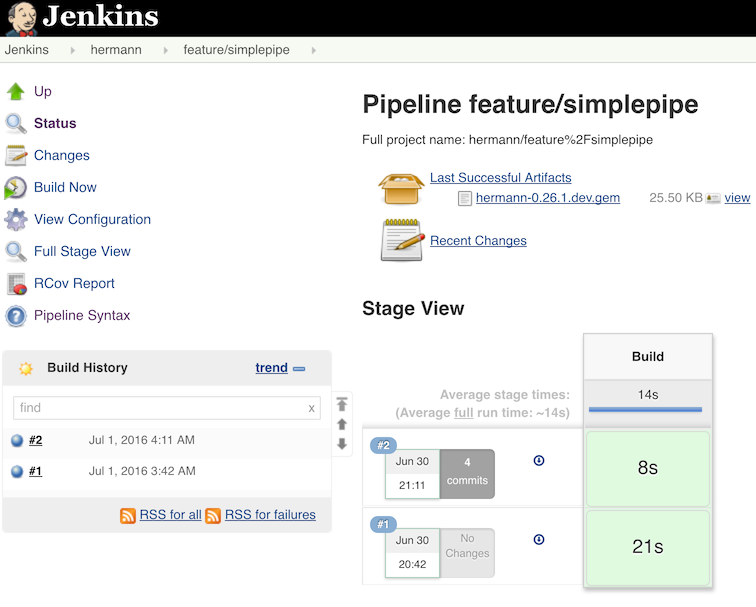
}
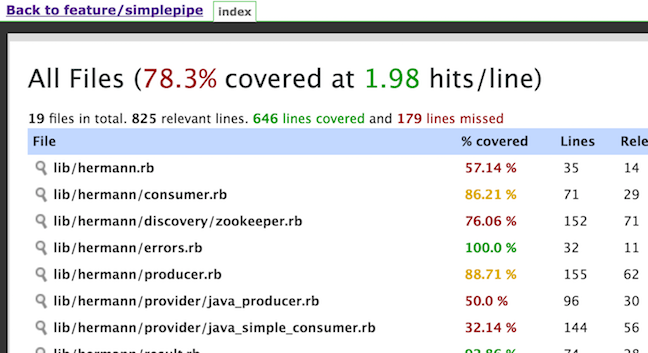
When I run this new pipeline I am rewarded with an RCov Report link on left side,
which I can follow to show the HTML report.
I even added the keepAll setting to let I can also go back an look at reports on old jobs as
more come in. As I said to to begin with, this is not as slick as what I
could do with a custom plugin, but it is much easier and works with any static
HTML.
![]()
↧
August 19, 2016, 12:42 pm
It’s been almost three months since we’ve released Jenkins 2.0, the first ever major version upgrade for this 10 year old project. The 2.x versions since then has been adopted by more than 20% of the users, but one segment of users who haven’t seen the benefits of Jenkins 2 is those who has been running LTS releases.
But that is no more! The new version of Jenkins LTS release we just released is 2.7.1, and now LTS users get to finally enjoy Jenkins 2.
This release also officially marks the end-of-life for Jenkins 1.x. There won’t be any future release of Jenkins 1.x beyond this point. If you are worried about the upgrade, don’t be! The core of Jenkins is still the same, and all the plugins & existing configuration will just work.
![]()
↧
August 19, 2016, 12:42 pm
We created new native packages for Jenkins 2.7.1 today. These replace the existing packages. Due to a release process issue, the packaging (RPM, etc.) was created the same way as Jenkins 1.x LTS, resulting in problems starting Jenkins on some platforms: While we dropped support for AJP in Jenkins 2.0, some 1.x packages had it enabled by default, resulting in an exception during startup.
These new packages for Jenkins 2.7.1, dated July 14, have the same scripts and parameters as Jenkins 2.x and should allow starting up Jenkins without problems. If you notice any further problems with the packaging, please report them in the packaging component.
![]()
↧