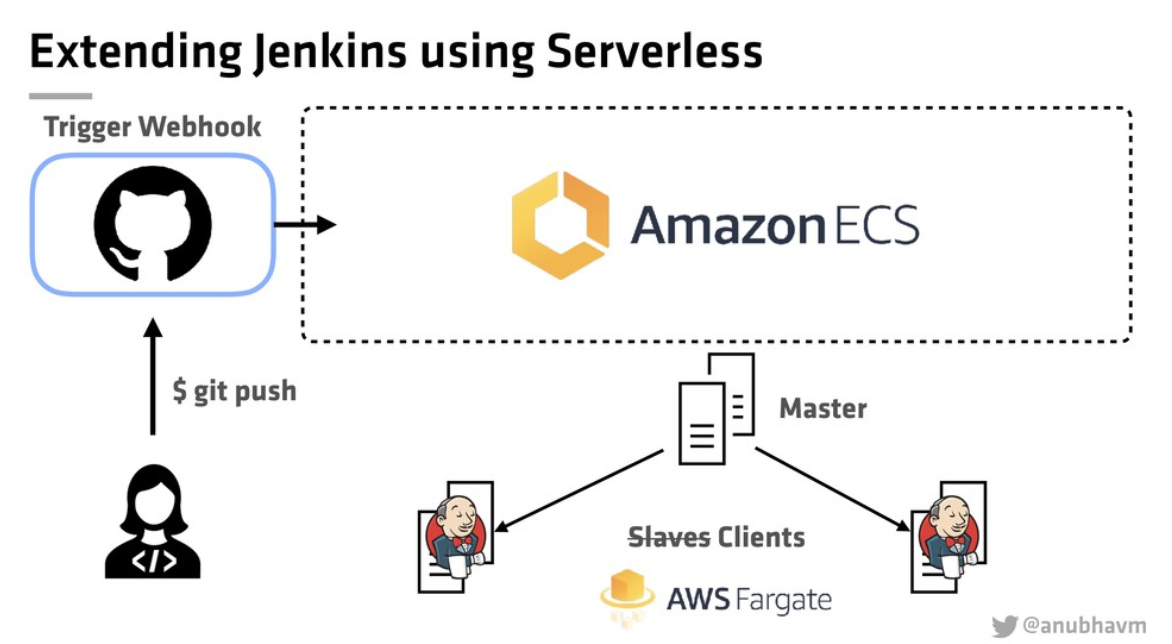
Jenkins infrastructure is continuously improving. The latest service to get some attention and major improvement is the Jenkins javadoc.
There were a number of issues affecting that service:
Irregular updates - Developers wouldn’t find the latest java documentation because of inadequate update frequence.
Broken HTTPS support - when users would go to the Javadoc site they would get an unsafe site warning and then an incorrect redirection.
Obsolete content - Javadoc was not cleaned up correctly and plenty of obsolete pages remained which confused end users.
As Jenkins servicesmigrate to Azure infrastructure, something that needed to be done was to move the javadoc service there as a standalone service. I took the same approach as jenkins.io, putting data on an azure file storage, using a nginx proxy in front of it and running on kubernetes. This approach brings multiple benefits:
We store static files on an azure file storage which brings data reliability, redundancy, etc.
We use Kubernetes Ingress to configure HTTP/HTTPS endpoint
We use Kubernetes Service to provide load balancing
We use Kubernetes deployment to deploy default nginx containers with azure file storage volume.
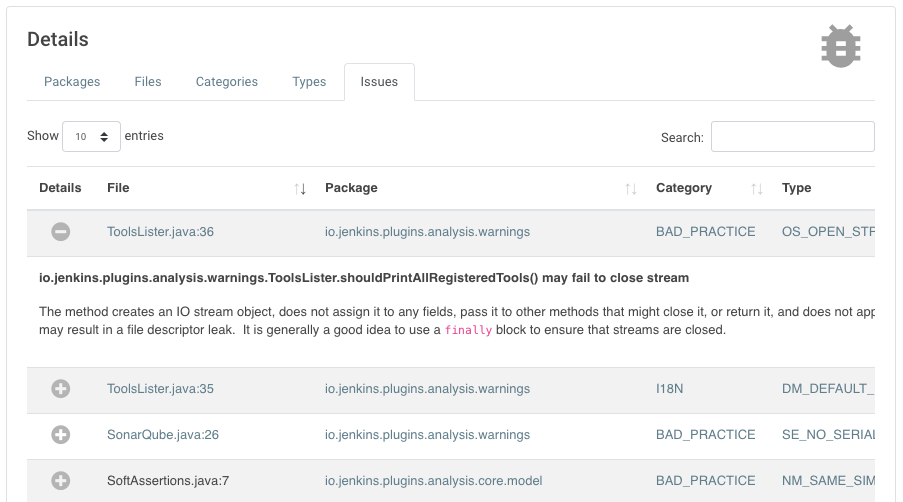
+----------------------+ goes on +------------------------------+
| Jenkins Developer |---------------->+ https://javadoc.jenkins.io |
+----------------------+ +------------------------------+
|
+-------------------------------------------------------------------|---------+
| Kubernetes Cluster: | |
| | |
| +---------------------+ +-------------------+ +-----------v------+ |
| | Deployment: Javadoc | | Service: javadoc <-----| Ingress: javadoc | |
+ +---------------------+ +-------------------+ +------------------+ |
| | |
| -----------------+ |
| | | |
| | | |
| +------------------------v--+ +--------v------------------+ |
| | Pod: javadoc | | Pod: javadoc | |
| | container: "nginx:alpine" | | container: "nginx:alpine" | |
| | +-----------------------+ | | +-----------------------+ | |
| | | Volume: | | | | Volume: | | |
| | | /usr/share/nginx/html | | | | /usr/share/nginx/html | | |
| | +-------------------+---+ | | +----+------------------+ | |
| +---------------------|-----+ +------|--------------------+ |
| | | |
+-----------------------|-----------------|-----------------------------------+
| |
| |
+--+-----------------+-----------+
| Azure File Storage: javadoc |
+--------------------------------+The javadoc static files are now generated by a Jenkinsjob regularly and then published from a trusted jenkins instance. We only update what has changed and remove obsolete documents. More information can be findhere
The next thing in continuously improving is also to look at the user experience of the javadoc to make it easier to discover javadoc for other components or versions. (Help Needed)
These changes all go towards improving the developer experience for those using javadocs and making life easier for core and plugin developers. See the new and improved javadoc service hereJenkins Javadoc.