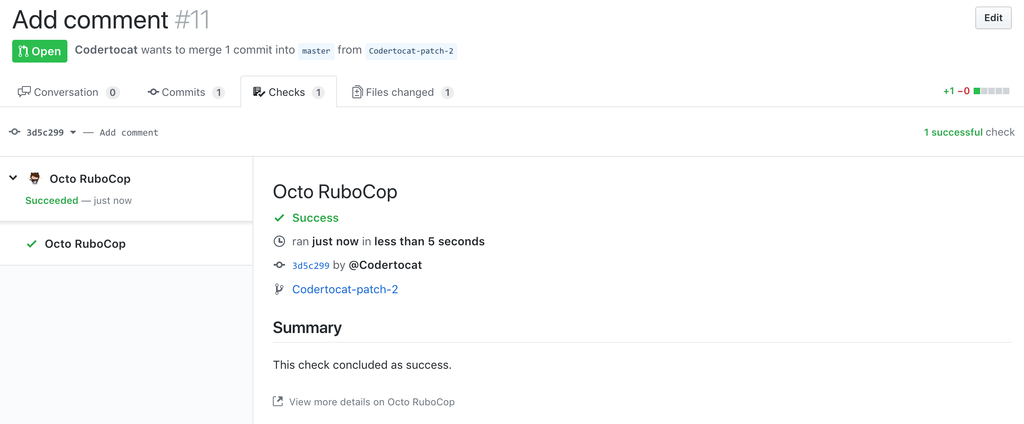
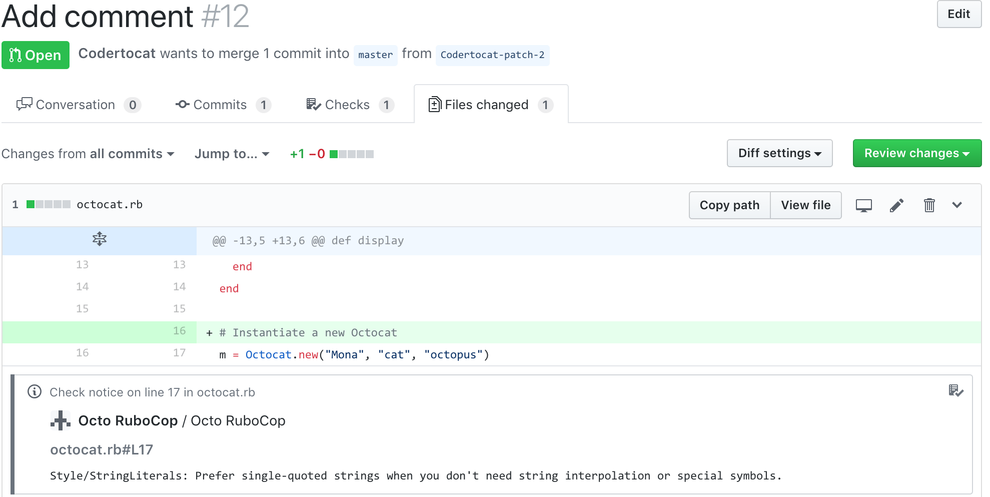
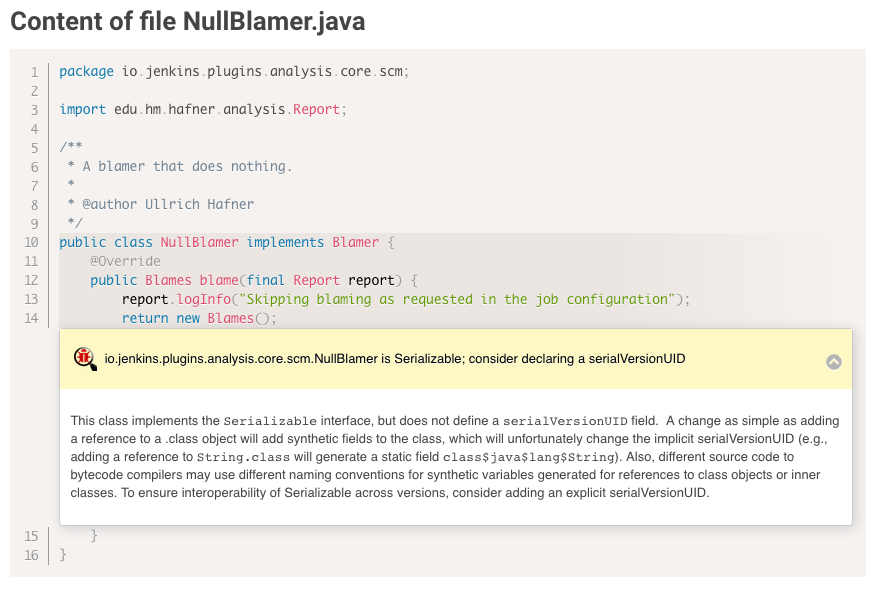
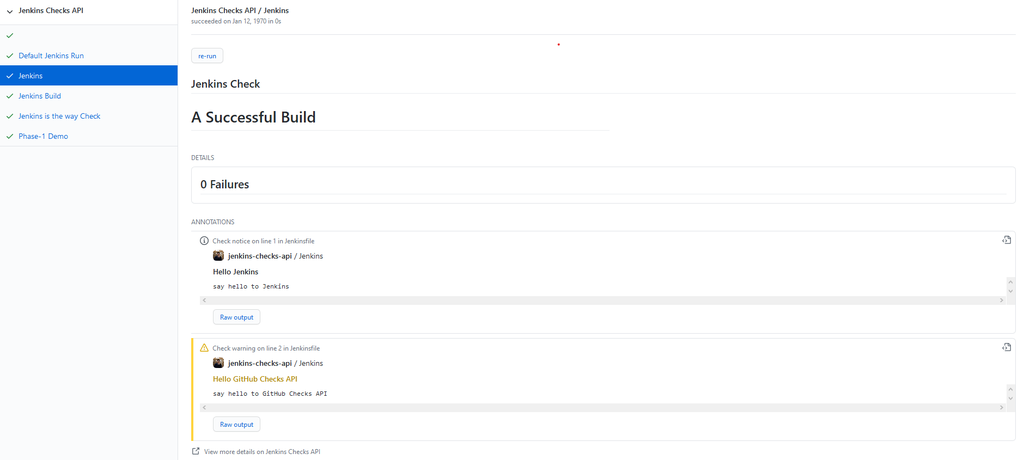
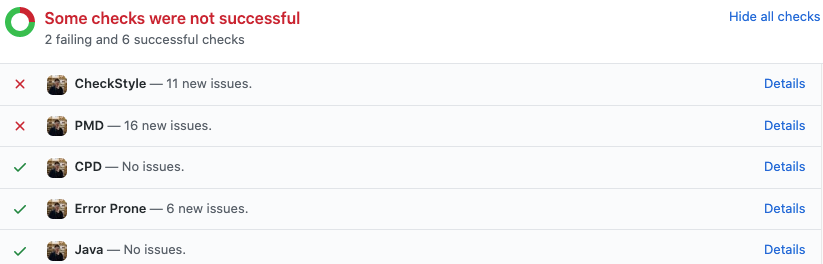
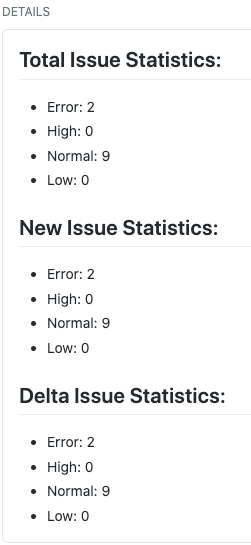
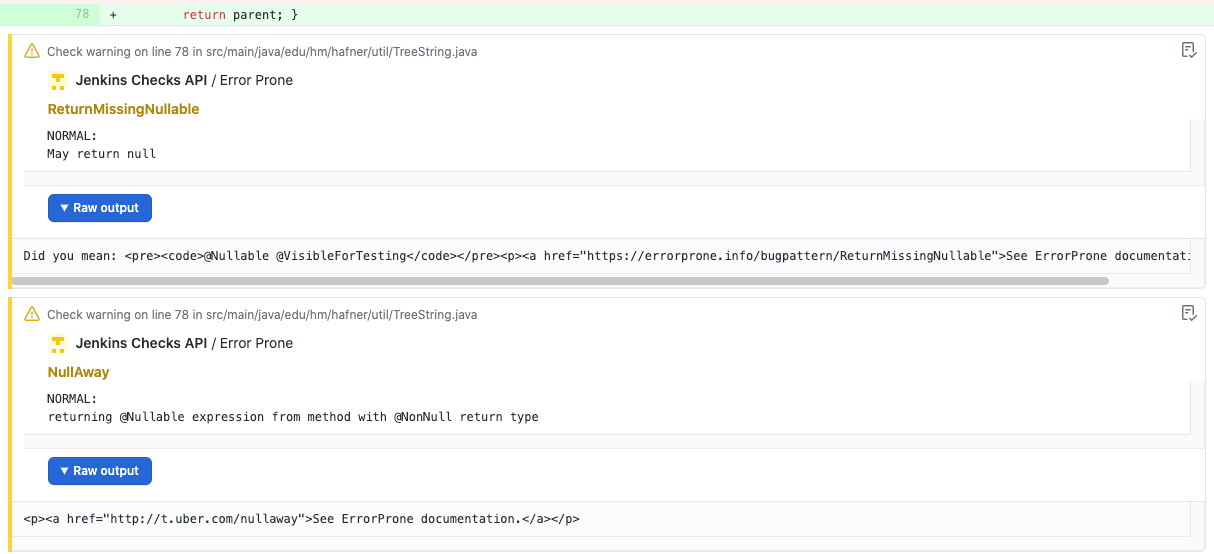
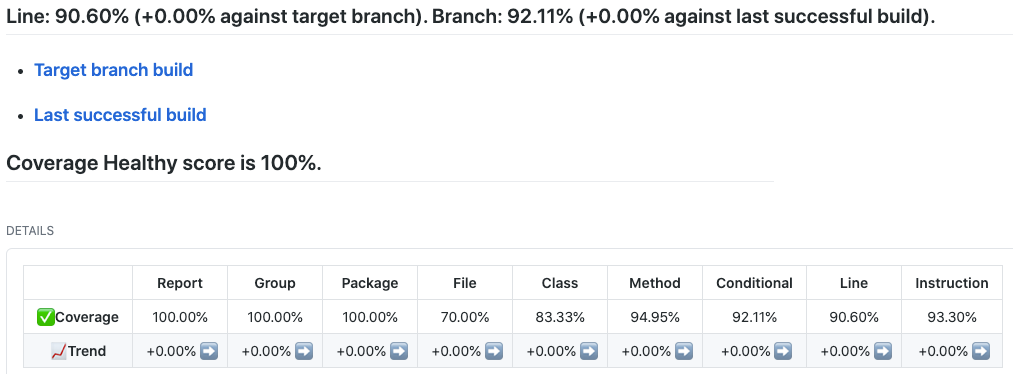
Externalizing fingerprint storage for Jenkins is a Google Summer of Code 2020 project. We are working on building a pluggable storage engine for fingerprints (see JEP-226).
File fingerprinting is a way to track which version of a file is being used by a job/build, making dependency tracking easy. The fingerprint engine of Jenkins can track usages of artifacts, credentials, files, etc. within the system. Currently, it does this by maintaining a local XML-based database which leads to dependence on the physical disk of the Jenkins master.
Allowing fingerprint storage to be moved to external storages decreases the dependence of Jenkins instances on the physical disk space and also allows for tracking the flow of fingerprints across instances of Jenkins connected to the same external storage.
Advantages of using external storage drivers:
Remove dependence on Jenkins master disk storage
Can configure pay-as-you-use cloud storages
Easy Backup Management
Better Reliability and Availability
Fingerprints can be tracked across Jenkins instances
Along with this API, we are also working on a reference implementation in the form of a plugin, powered by Redis.
As phase 1 of this project comes to an end, this blog post serves as a summary of the progress we made to the entire Jenkins community.
Current State
The new API introduced in Jenkins core is under review. Once merged, it will offer developers to extend it to build external fingerprint storage plugins.
The Redis Fingerprint Storage Plugin is alpha release ready. We would immensely appreciate any feedback.
Introducing the new API for plugin developers
With PR-4731, we introduce a new fingerprint storage API, allowing configuring custom storage engines.
We exposed the following methods in the new FingerprintStorage class:
void save()Saves the given Fingerprint in the storage.
Fingerprint load(String id)Returns the Fingerprint with the given unique ID. The unique ID for a fingerprint is defined by Fingerprint#getHashString().
void delete(String id)Deletes the Fingerprint with the given unique ID.
boolean isReady()Returns true if there is some data in the fingerprint database corresponding to the particular Jenkins instance.
Introducing Redis Fingerprint Storage Plugin
Redis Fingerprint Storage Plugin uses the new External Fingerprint Storage API to store the fingerprints in a Redis instance.
Installation:
The alpha release (version 0.1-alpha-1) for the plugin was drafted, and can be installed using the experimental update center.
Follow along the following steps after running Jenkins to download and install the plugin:
Select
Manage JenkinsSelect
Manage PluginsGo to
AdvancedtabConfigure the Update Site URL as: https://updates.jenkins.io/experimental/update-center.json
Click on
Submit, and then press theCheck Nowbutton.Go to
Availabletab.Search for
Redis Fingerprint Storage Pluginand check the box along it.Click on
Install without restart
The plugin should now be installed on your system.
Usage
Once the plugin has been installed, you can configure the Redis server details by following the steps below:
Select
Manage JenkinsSelect
Configure SystemScroll to the section
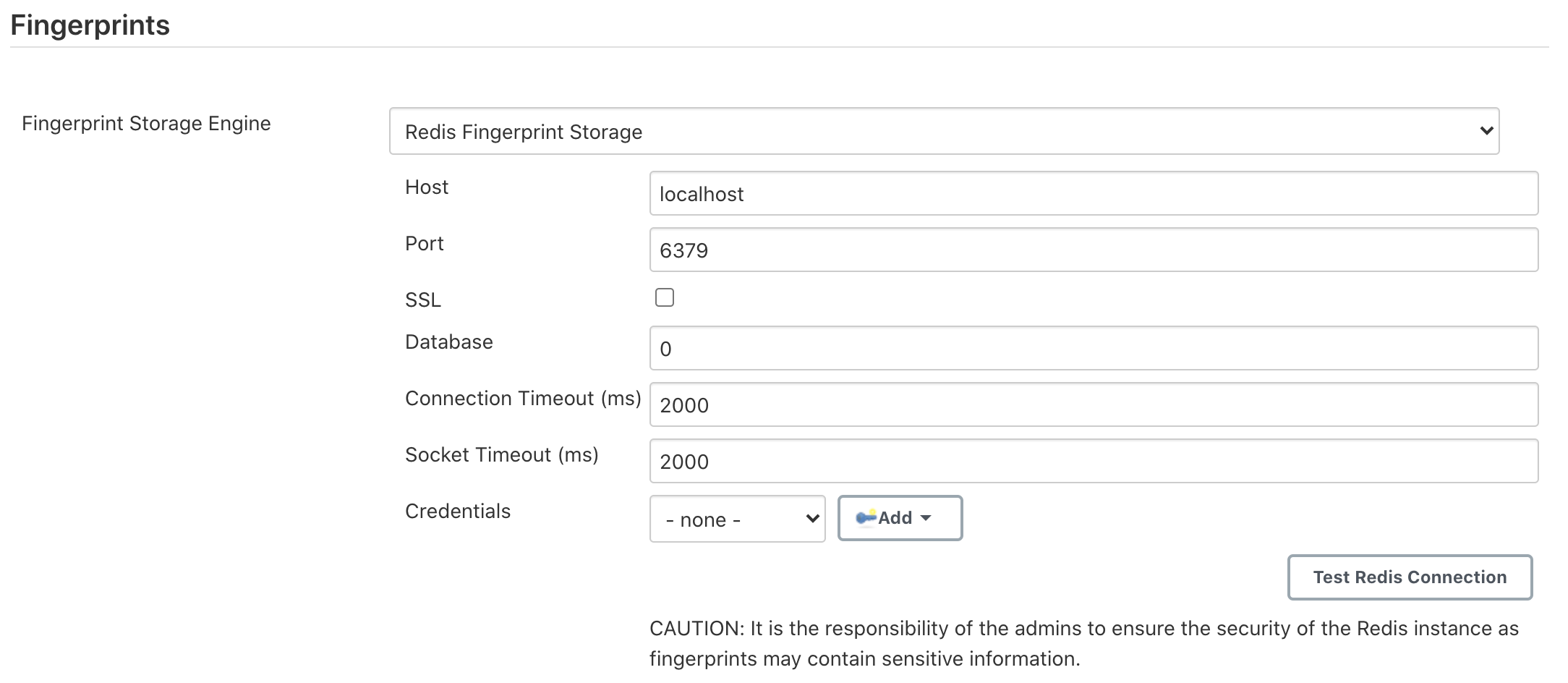
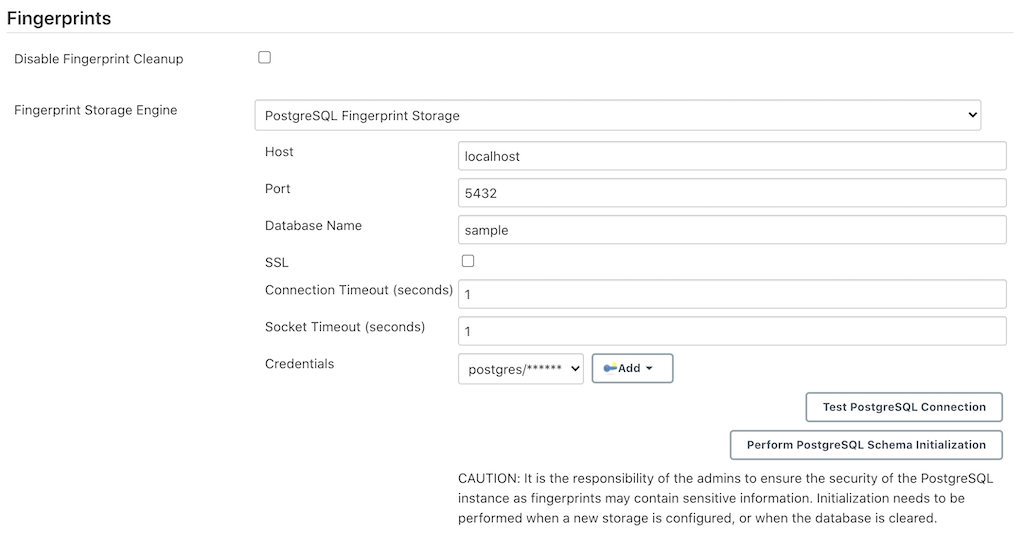
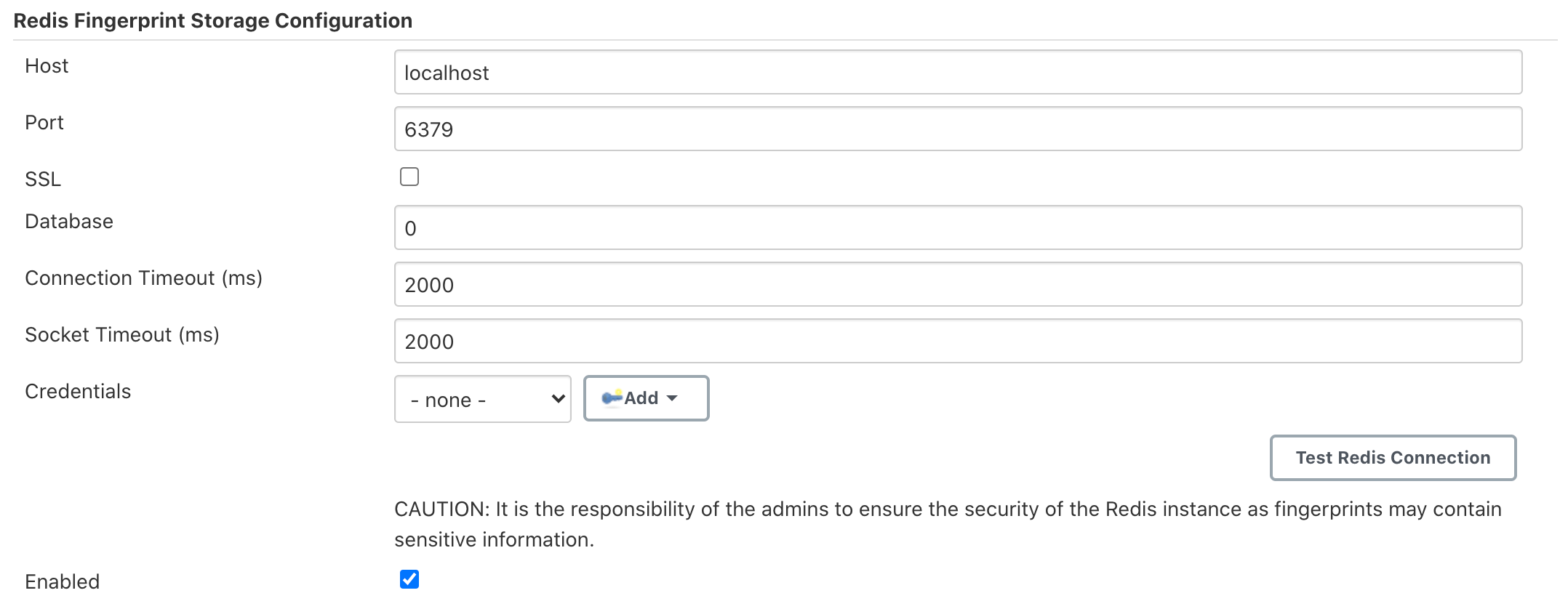
Redis Fingerprint Storage Configurationand fill in the required details:![Configure Redis]()
Host- Enter hostname where Redis is runningPort- Specify the port on which Redis is runningSSL- Click if SSL is enabledDatabase- Redis supports integer indexed databases, which can be specified here.Connection Timeout- Set the connection timeout duration in milliseconds.Socked Timeout- Set the socket timeout duration in milliseconds.Credentials- Configure authentication using username and password to the Redis instance.Enabled- Check this to enable the plugin (Note: This is likely to be removed very soon, and will be enabled by default.)
Use the
Test Redis Connectionto verify that the details are correct and Jenkins is able to connect to the Redis instance.Press the
Savebutton.Now, all the fingerprints produced by this Jenkins instance should be saved in the configured Redis server!
Future Work
Some of the topics we aim to tackle in the next phases include extending the API, fingerprint cleanup, migrations (internal→external, external→internal, external→external), tracing, ORM, implementing the saveable listener, etc.
Acknowledgements
The Redis Fingerprint Storage plugin is built and maintained by the Google Summer of Code (GSoC) Team forExternal Fingerprint Storage for Jenkins.
Special thanks to Oleg Nenashev, Andrey Falko, Mike Cirioli, Jesse Glick, and the entire Jenkins community for all the contribution to this project.
Reaching Out
Feel free to reach out to us for any questions, feedback, etc. on the project’s Gitter Channel or the Jenkins Developer Mailing list
We use Jenkins Jira to track issues.
Feel free to file issues under redis-fingerprint-storage-plugin component.