| This guest post was originally published on Wolox’s Medium account here. |
A few years ago our CTO wrote about building aContinuous Integration server for Ruby On Rails using Jenkins and docker. The solution has been our CI pipeline for the past years until we recently decided to make an upgrade. Why?
Jenkins version was way out of date and it was getting difficult to upgrade
Wolox has grown significantly over the past years and we’ve been experiencing scaling issues
Very few people knew how to fix any issues with the server
Configuring jobs was not an easy task and that made our project kickoff process slower
Making changes to the commands that each job runs was not easy and not many people had permissions to do so. Wolox has a wide range of projects, with a wide variety of languages which made this problem even bigger.
Taking into account these problems, we started digging into the newest version of Jenkins to see how we could improve our CI. We needed to build a new CI that could, at least, address the following:
Projects must be built using Docker. Our projects depend on one or multiple docker images to run (app, database, redis, etc)
Easy to configure and replicate if necessary
Easy to add a new project
Easy to change the building steps. Everyone working on the project should be able to change if they want to run npm install or yarn install.
Installing Jenkins and Docker
Installing Jenkins is straightforward. You can visitJenkins Installation page and choose the option that best suits your needs.
Here are the steps we followed to install Jenkins in AWS:
sudo rpm — import https://pkg.jenkins.io/debian/jenkins.io.key
sudo wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenkins.io/redhat/jenkins.repo
sudo yum install java-1.8.0 -y
sudo yum remove java-1.7.0-openjdk -y
sudo yum install jenkins -y
sudo yum update -y
sudo yum install -y dockerAutomatically adding projects from Github
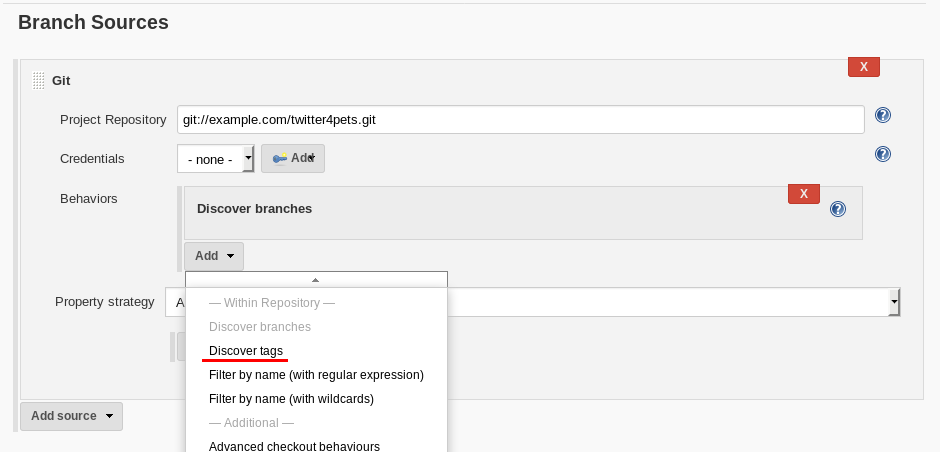
Adding projects automatically from Github can be achieved using theGitHub Branch Source Plugin. It allows Jenkins to scan a GitHub organization for projects that match certain rules and add them to Jenkins automatically. The only constraint that all branches must meet in order to be added is that they contain a Jenkinsfile that explains how to build the project.
Easy to change configuration
Not so easy to change configuration
One of the biggest pains we had with our previous Jenkins was the difficulty of changing the steps necessary to build the project. If you looked at a project’s build steps, you would find something like this:
#!/bin/bash +x
set -e
# Remove unnecessary files
echo -e "\033[34mRemoving unnecessary files...\033[0m"
rm -f log/*.log &> /dev/null || true &> /dev/null
rm -rf public/uploads/* &> /dev/null || true &> /dev/null
# Build Project
echo -e "\033[34mBuilding Project...\033[0m"
docker-compose --project-name=${JOB_NAME} build
# Prepare test database
COMMAND="bundle exec rake db:drop db:create db:migrate"
echo -e "\033[34mRunning: $COMMAND\033[0m"
docker-compose --project-name=${JOB_NAME} run \
-e RAILS_ENV=test web $COMMAND
# Run tests
COMMAND="bundle exec rspec spec"
echo -e "\033[34mRunning: $COMMAND\033[0m"
unbuffer docker-compose --project-name=${JOB_NAME} run web $COMMAND
# Run rubocop lint
COMMAND="bundle exec rubocop app spec -R --format simple"
echo -e "\033[34mRunning: $COMMAND\033[0m"
unbuffer docker-compose --project-name=${JOB_NAME} run -e RUBYOPT="-Ku" web $COMMANDAnd some post build steps that cleaned up the docker:
#!/bin/bash +x
docker-compose --project-name=${JOB_NAME} stop &> /dev/null || true &> /dev/null
docker-compose --project-name=${JOB_NAME} rm --force &> /dev/null || true &> /dev/null
docker stop `docker ps -a -q -f status=exited` &> /dev/null || true &> /dev/null
docker rm -v `docker ps -a -q -f status=exited` &> /dev/null || true &> /dev/null
docker rmi `docker images --filter 'dangling=true' -q --no-trunc` &> /dev/null || true &> /dev/nullAlthough these commands are not complex, changing any of them required someone with permissions to modify the job and an understanding ofwhat needed to be done.
Jenkinsfile to the rescue… or not
With the current Jenkins version, we can take advantage ofJenkins Pipeline and model our build flow in a file. This file is checked into the repository and, therefore, anyone with access to it can change the build steps. Yay!
Jenkins Pipeline even has support for:
Docker andmultiple images can be used for a build!
Setting environment variables with withEnv and many other built -in functions that can be foundhere.
This makes a perfect case for Wolox. We can have our build configuration in a file that’s checked into the repository and can be changed by anyone with write access to it. However, a Jenkinsfile for a simple rails project would look something like this:
# sample Jenkinsfile. Might not compile
node {
checkout scm
withEnv(['MYTOOL_HOME=/usr/local/mytool']) {
docker.image("postgres:9.2").withRun() { db ->
withEnv(['DB_USERNAME=postgres', 'DB_PASSWORD=', "DB_HOST=db", "DB_PORT=5432"]) {
docker.image("redis:X").withRun() { redis ->
withEnv(["REDIS_URL=redis://redis"]) {
docker.build(imageName, "--file .woloxci/Dockerfile .").inside("--link ${db.id}:postgres --link ${redis.id}:redis") {
sh "rake db:create"
sh "rake db:migrate"
sh "bundle exec rspec spec"
}
}
}
}
}
}
}This file is not only difficult to read, but also difficult to change. It’s quite easy to break things if you’re not familiar with Groovy and even easier if you know nothing about how Jenkins’ pipeline works. Changing or adding a new Docker image isn’t straightforward and might lead to confusion.
Configuring Jenkins Pipeline via YAML
Personally, I’ve always envied simple configuration files for CIs and this time it was our chance to build CI that could be configured using a YAML file. After some analysis we concluded that a YAML like this one would suffice:
config:dockerfile: .woloxci/Dockerfileproject_name: some-project-nameservices:
- postgresql
- redissteps:analysis:
- bundle exec rubocop -R app spec --format simple
- bundle exec rubycritic --path ./analysis --minimum-score 80 --no-browsersetup_db:
- bundle exec rails db:create
- bundle exec rails db:schema:loadtest:
- bundle exec rspecsecurity:
- bundle exec brakeman --exit-on-erroraudit:
- bundle audit check --updateenvironment:RAILS_ENV: testGIT_COMMITTER_NAME: aGIT_COMMITTER_EMAIL: bLANG: C.UTF-8It outlines some basic configuration for the project, environment variables that need to be present during the run, dependentservices, and our build steps.
Jenkinsfile + Shared Libraries = WoloxCI
After investigating for a while about Jenkins and the pipeline, we found that we could extend it withshared libraries. Shared libraries are written in groovy and can be imported into the pipeline and executed when necessary.
If you look carefully at this Jenkinsfile, we see that the code is a chain of methods calls that receive a closure, where we execute another method passing a new closure to it.
# sample Jenkinsfile. Might not compile
node {
checkout scm
withEnv(['MYTOOL_HOME=/usr/local/mytool']) {
docker.image("postgres:9.2").withRun() { db ->
withEnv(['DB_USERNAME=postgres', 'DB_PASSWORD=', "DB_HOST=db", "DB_PORT=5432"]) {
docker.image("redis:X").withRun() { redis ->
withEnv(["REDIS_URL=redis://redis"]) {
docker.build(imageName, "--file .woloxci/Dockerfile .").inside("--link ${db.id}:postgres --link ${redis.id}:redis") {
sh "rake db:create"
sh "rake db:migrate"
sh "bundle exec rspec spec"
}
}
}
}
}
}
}Groovy is flexible enough to allow this same declarative code to be created at runtime, making our dream of using a YAML to configure our job come true!
Introducing Wolox-CI
That’s how wolox-ci was born- our shared library for Jenkins!
With wolox-ci, our Jenkinsfile is now reduced to:
@Library('wolox-ci') _
node {
checkout scm
woloxCi('.woloxci/config.yml');
}Now it simply checks out the code and then calls wolox-ci. The library reads yaml file like this one
config:dockerfile: .woloxci/Dockerfileproject_name: some-project-nameservices:
- postgresql
- redissteps:analysis:
- bundle exec rubocop -R app spec --format simple
- bundle exec rubycritic --path ./analysis --minimum-score 80 --no-browsersetup_db:
- bundle exec rails db:create
- bundle exec rails db:schema:loadtest:
- bundle exec rspecsecurity:
- bundle exec brakeman --exit-on-erroraudit:
- bundle audit check --updateenvironment:RAILS_ENV: testGIT_COMMITTER_NAME: aGIT_COMMITTER_EMAIL: bLANG: C.UTF-8and builds the Jenkinsfile to get your job running on the fly.
The nice part about having a shared library is that we can extend and fix our library in a centralized way. Once we add new code, the library is automatically updated in Jenkins which will notify all of our jobs with the update.
Since we have projects in different languages we use Docker to build the testing environment. WoloxCI assumes there is a Dockerfile to build and will run all the specified commands inside the container.
Woloxci config.yml
Config
The first part of the config.yml file specifies some basic configuration: project’s name and Dockerfile location. The Dockerfile is used to build the image where the commands will be run.
Services
This section describes which services will be exposed to the container. Out of the box, WoloxCI has support for postgresql, mssql andredis. You can also specify the docker image version you want! It is not hard to add a new service. You just need to add the corresponding file at
and modify how the services are parsed
Wrapping up
WoloxCI is still being tested with a not-so-small sample of our projects. The possibility of changing the build steps through a YAML file makes it accessible for everyone and that is a great improvement in our CI workflow.
Docker gives us the possibility of easily changing the programming language without making any changes to our Jenkins installation and Jenkins’ Github Organization feature automatically adds new projects when a new repository with a Jenkinsfile is detected.
All of these improvements have reduced the time we spend maintaining Jenkins significantly and give us the possibility of easily scaling without any extra configuration.
This library is working in our CI but it still can be improved. If you would like to add features, feel free tocontribute!