This is a guest post by Steven Terrana, a Lead Technologist atBooz Allen Hamilton and principal engineer working on the Templating Engine Plugin. He participates in the Pipeline Authoring Special Interest Group. |
Implementing DevSecOps practices at the enterprise scale is challenging. With multiple programming languages, automated testing frameworks, and security compliance tools being used by different applications within your organization, it becomes difficult to build and maintain pipelines for each team.
Most pipelines are going to follow the same generic workflow regardless of which specific tech stack is employed by an application. The Templating Engine Plugin (abbreviated as JTE for Jenkins Templating Engine) allows you to capture this efficiency by creating tool-agnostic, templated workflows to be reused by every team.
As technology consultants with clients in both the public and private sectors, at Booz Allen we found ourselves building DevSecOps pipelines from scratch for every new project. Through developing the Jenkins Templating Engine, we’ve seen pipeline development decrease from months to days now that we can reuse tool integrations while bringing a new level of governance to Jenkins pipelines.
Pipeline Templating
Organizations benefit from letting application developers focus on what they do best: building applications. Supporting this means building a centralized DevOps team responsible for maintaining platform infrastructure and creating CI/CD pipelines utilized by development teams.
With the rise of microservice-based architectures, a centralized DevOps teams can support many different development teams simultaneously; all of whom may be leveraging different programming languages and automated testing tools.
While the tools may differ between development teams, the workflow is often the same: unit test, static code analysis, build and publish an artifact, deploy it, and then perform different types of testing against the deployed application.
| The Templating Engine Plugin allows you to remove the Jenkinsfile from each repository by defining a common workflow for teams to inherit. Instead of an entire pipeline definition in each repository, teams supply a configuration file specifying which tools to use for the workflow. |
JTE in Action
Let’s walk through a bare bones example to demonstrate the reusability of templates:
unit_test()
build()
static_code_analysis()Templates leverage Steps contributed by Libraries to outline a workflow teams must implement. While a template does get executed just like any other Jenkinsfile (meaning that the standard scripted and declarative syntax is supported), the goal of a template should be to read like plain English and avoid any technical implementation.
| Leveraging templates in this way lets you separate the business logic (what should happen when) of your pipeline from thetechnical implementation (what’s actually going to happen). The result of this is a CI/CD pipeline that’s proven to be significantly easier to manage when supporting multiple teams simultaneously. |
The steps outlined by this template (unit_test, build, and static_code_analysis) have been named generically on purpose. This way teams can specify different libraries to use while sharing the same pipeline.
Implementing the Template
Implementing a shareable pipeline with the Templating Engine requires a few key components:
Pipeline Template: Outline the workflow to be performed
Libraries: Provide technical implementations of the steps of the workflow
Configuration Files: Specify which libraries to use and their configuration
Step 1: Create a Pipeline Configuration Repository
A Pipeline Configuration Repository is used to store common configurations and pipeline templates inherited by teams.
This example Pipeline Configuration Repository will later be configured as part of a Governance Tier: the mechanism in JTE that allows you to build hierarchical configurations representing your organization.
A Governance Tier holds three things:
Pipeline Templates
A list of Library Sources
The tier’s configuration file (
pipeline_config.groovy)
| The pipeline templates and the configuration file for a Governance Tier are stored in the pipeline configuration repository. |
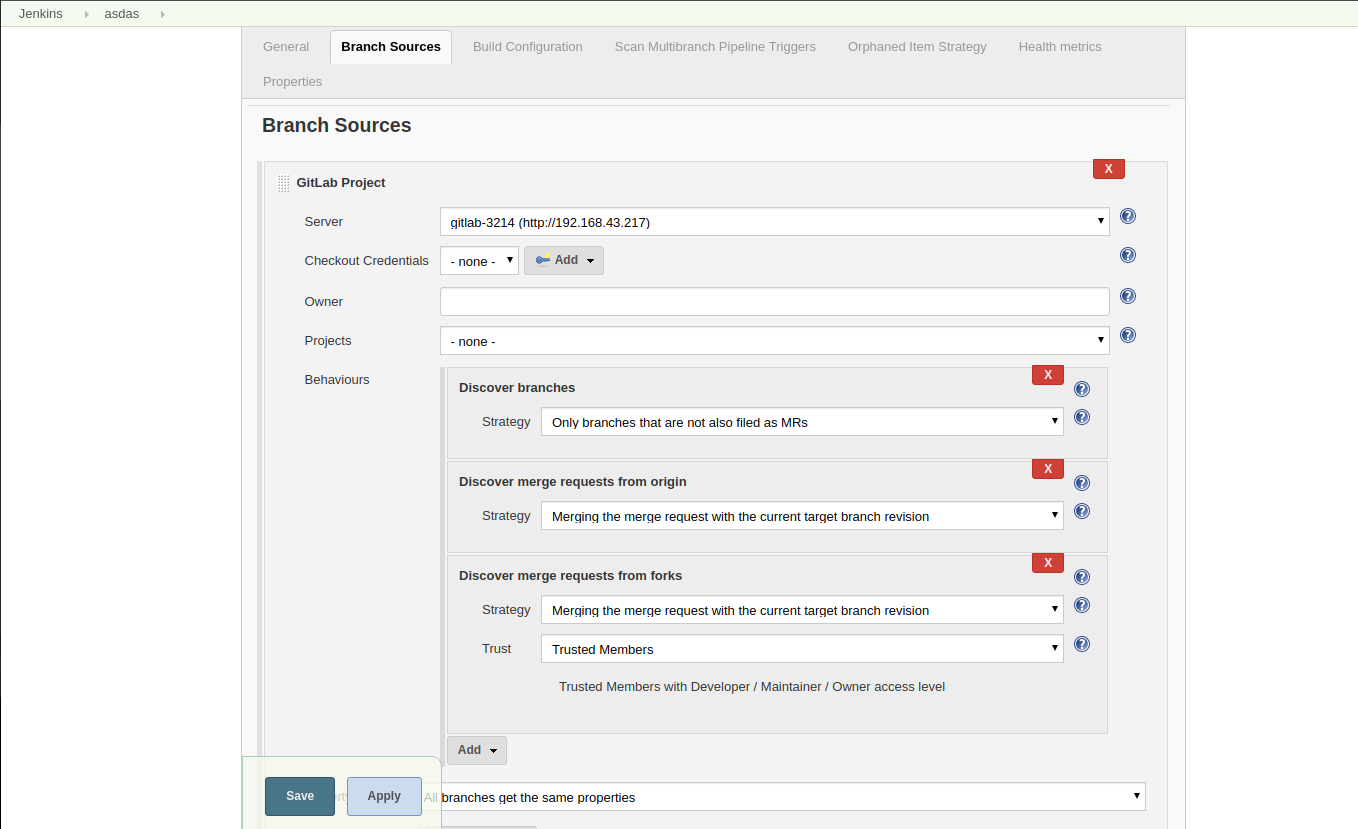
When configuring the Governance Tier in Jenkins, you will provide a source code management location for a repository that contains the above components as well as the base directory where these artifacts can be found.
Step 2: Create the Pipeline Template
Next, we’ll create a Jenkinsfile for the Governance Tier. In JTE, the Jenkinsfile is the default pipeline template that an execution will use.
unit_test()
build()
static_code_analysis()Step 3: Create the Libraries
The Templating Engine Plugin has implemented a version of Jenkins Shared Libraries to enhance the reusability of libraries. A library is a root directory within a source code repository that has been configured as a Library Source on a Governance Tier.
In our example, the pipeline template needs to perform unit testing, package an artifact, and run static code analysis.
Let’s assume that we have some teams using gradle and some teams using maven to build and test their application but they will both use SonarQube to perform static code analysis.
In this scenario, we should create gradle, maven, and sonarqube libraries.
|- gradle/ \-- build.groovy \-- unit_test.groovy |- maven/ \-- build.groovy \-- unit_test.groovy |- sonarqube/ \-- static_code_analysis.groovy
Step 4: Implement the Steps
Implementing a library step is exactly the same as just writing regular global variables as part of the default Jenkins Shared Libraries.
For the purposes of this demonstration, we will just have each step print out the step name and contributing library.
void call(){
println "gradle: build()"
}| Read more about Library Development within JTE. |
Step 5: Create the Configuration Files
The configuration file for JTE is named pipeline_config.groovy.
In the Governance Tier we’ll create a configuration file specifying common configurations between the applications. In this case, both applications are using the sonarqube library:
libraries{
merge = true// allow individual apps to contribute additional libraries
sonarqube
}Next, we’ll create two more repositories representing the maven and gradle applications. Within those repositories all we’ll need is an application-specific pipeline_config.groovy file.
These repositories both contain an application pipeline_config.groovy configuration file.
libraries{
maven
}libraries{
gradle
}Step 6: Configure the Governance Tier in Jenkins
Now that we have a Pipeline Configuration Repository and a Library Source Repository, we can configure a Governance Tier in Jenkins:

This configuration shown in the image above can be found under Manage Jenkins >> Configure System |
| Through the Templating Engine, you can create a pipeline governance hierarchy matching your organization’s taxonomy by representing this structure via Folders in Jenkins. |
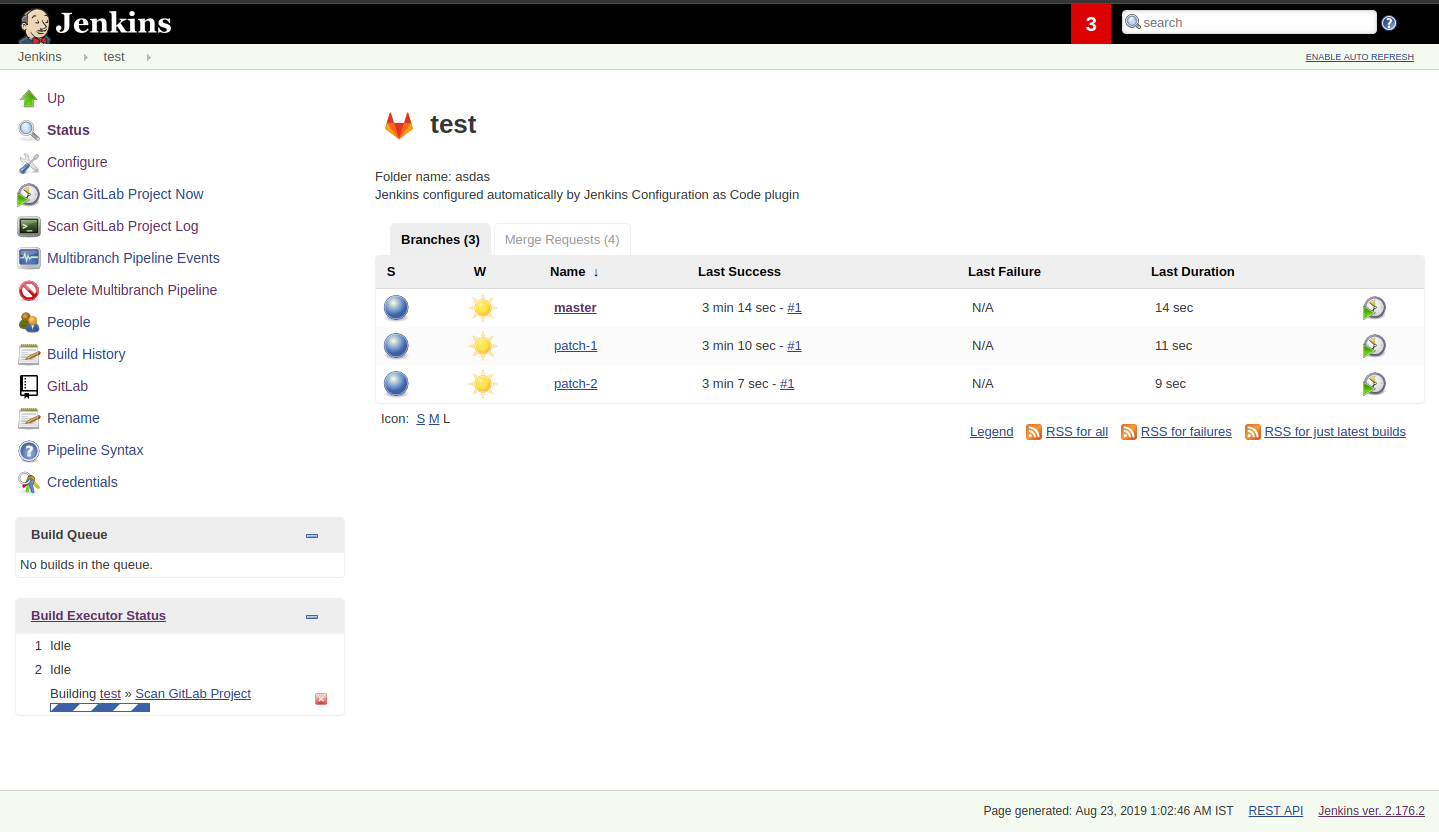
Step 7: Create a Multibranch Pipeline for Both Applications
When creating Multibranch Pipeline Projects for each app, the Templating Engine plugin supplies a new Project Recognizer
called Jenkins Templating Engine. This sets the project to use the Templating Engine framework for all branches within the
repository.

| You can also set the Jenkins Templating Engine project recognizer for a GitHub Organization project, enabling you to easily share the same pipeline across an entire Github Organization! |
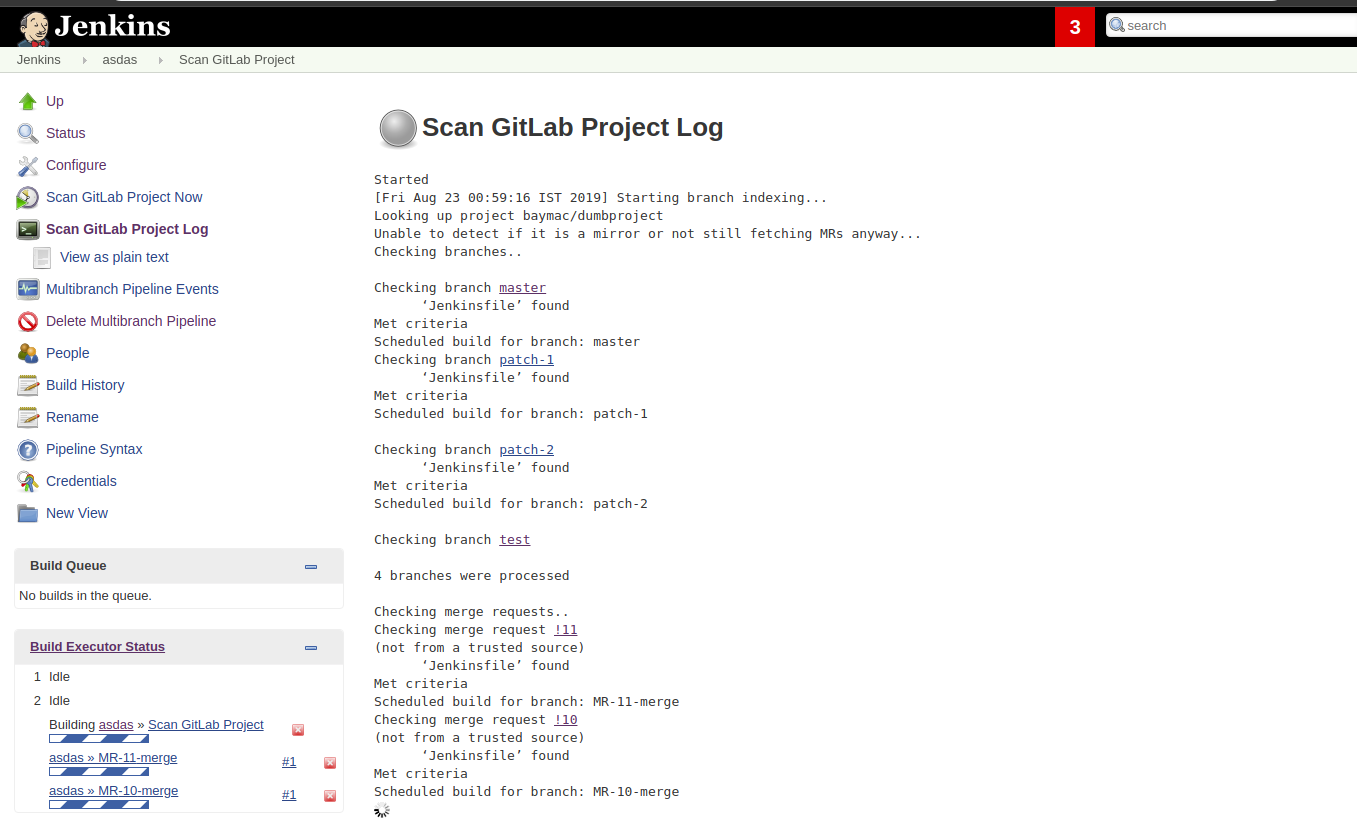
Step 8: Run the Pipelines
That’s it! Now, both applications will leverage the exact same pipeline template while having the flexibility to select which tools should be used during each phase of the workflow.
Below is sample output from the console log from both applications pipeline runs:
[JTE] Obtained Template Configuration File pipeline_config.groovy from git https://github.com/steven-terrana/example-jte-configuration [JTE] Obtained Template Configuration File pipeline_config.groovy from git https://github.com/steven-terrana/example-jte-app-gradle.git [JTE] Loading Library sonarqube from git https://github.com/steven-terrana/example-jte-libraries.git [JTE] Loading Library gradle from git https://github.com/steven-terrana/example-jte-libraries.git ... [JTE] Obtained Template Jenkinsfile from git https://github.com/steven-terrana/example-jte-configuration [JTE][Step - gradle/unit_test] [Pipeline] echo gradle: unit_test() [JTE][Step - gradle/build] [Pipeline] echo gradle: build() [JTE][Step - sonarqube/static_code_analysis] [Pipeline] echo sonarqube: static_code_analysis() [Pipeline] End of Pipeline
[JTE] Obtained Template Configuration File pipeline_config.groovy from git https://github.com/steven-terrana/example-jte-configuration [JTE] Obtained Template Configuration File pipeline_config.groovy from git https://github.com/steven-terrana/example-jte-app-maven.git [JTE] Loading Library sonarqube from git https://github.com/steven-terrana/example-jte-libraries.git [JTE] Loading Library maven from git https://github.com/steven-terrana/example-jte-libraries.git ... [JTE] Obtained Template Jenkinsfile from git https://github.com/steven-terrana/example-jte-configuration [JTE][Step - maven/unit_test] [Pipeline] echo maven: unit_test() [JTE][Step - maven/build] [Pipeline] echo maven: build() [JTE][Step - sonarqube/static_code_analysis] [Pipeline] echo sonarqube: static_code_analysis() [Pipeline] End of Pipeline
Benefits of the Templating Engine

Apply Organizational Governance
Leveraging the Templating Engine Plugin will allow you to define enterprise-scale, approved workflows that can be used by teams regardless of what tools are being used. This top-down approach makes scaling and enforcing DevSecOps principles significantly easier within your organization.
Optimize Code Reuse
There’s really no need for every team in your organization to figure out how to do the same things over and over again. At Booz Allen, we have seen pipeline development time decrease from months to days as we have continuously reused and expanded upon our Templating Engine library portfolio as part of our Solutions Delivery Platform.
Simplify Pipeline Maintainability
Often DevOps engineers find themselves building and supporting pipelines for multiple development teams at the same time. By decoupling the workflow from the technical implementation and consolidating the pipeline definition to a centralized location, the Templating Engine plugin allows DevOps engineers to scale much faster.
Get Involved!
The Templating Engine Plugin has been open sourced and made available in the Jenkins Update Center.
We always appreciate feedback and contributions! If you have an interesting use case or would like to ask questions, try the templating-engine-plugin on Gitter.